論文紹介: paGAN: Real-time Avatars Using Dynamic Textures
こんにちは、iwanao731です。Facial関連論文めちゃめちゃ読んでるので忘れないうちに!
概要
paGAN: Real-time Avatars Using Dynamic Textures Nagano et al., SIGGRAPH ASIA 2018
入力画像一枚の顔から、Identityを保ったままfine-sclaeの新たな表情を生成する技術に関する論文。ニュートラルの表情一枚だけだと、別の表情の際のシワ等の効果を足すことは難しいが、それを何人もの人の無表情と表情の組み合わせから、conditional Generative Adversarial Networkを使用し、もっともらしい表情やその際のシワ等の情報を推定することを可能にしている。顔だけでなく、目や口内の情報も生成可能。ポイントは形状と表情テクスチャに相関関係があることを仮定し、表情生成の際に動的にテクスチャをブレンドする点。
関連研究
近年、画像上の表情を変える画像ベースの技術[1][2][3][4]が提案されてきているが、CGモデルのように様々な角度で見ることは難しい。
- [1] StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation, Choi et al., (2017)
- [2] ExprGAN: Facial Expression Editing with Controllable Expression Intensity, Ding et al., (2017)
- [3] Progressive Growing of Gans for Improved Quality, Stability and Variation, Karras et al., (2017)
- [4] Geometry Guided Adversarial Facial Expression Synthesis, (arXiv'17)
特に以下2つの論文は、二次元上の表情のリターゲットを実時間で再現することを可能にしている。
- [5] Bringing portraits to life (SIGGRAPH'17)
- [6] Realistic Dynamic Facial Textures from a Single Image using GANs, Olszewski et al., (ICCV'17)
しかしながら、もとの人物の表情や構内情報を別の人物に転写すると違和感が大きい上に、新たなsubjectへのトレーニングに手間がかかる。本論文では転写は行わず、無表情の単一画像から、UV空間上の高精細なもっともらしい表情画像や口内、眼球画像を生成する。また、一度トレーニングしたらそれ以降はどんな入力画像人物に対しても違和感なく適応することができる。
また、従来のGANを用いた手法は写実的な顔表現が可能だが、その制御が難しくスキントーンやライティングに対する調整が難しかったが、paGAN (photo-real avatar GAN)は、テクスチャをそれぞれに分解することにより、その調整を可能にしている。それらのテクスチャは最終的に3D morphable modelが入力画像にfitすることによって実現される。
paGANの生成部分はGPUが必要となるため、スマートフォンデバイスでの実現は難しいが、一度計算したFACSに基づいた各表情のテクスチャ(sparse set of key expression textures)を生成すれば、その情報を元にスマートフォン上でも表情を再現することができる。
[7] Real-Time Facial Animation with Image-based Dynamic Avatars, Cao et al., SIGGRAPH 2016 [ 論文 ]
Caoらの手法とは異なり、本論文はimage-based facial blendshapesであるため、複雑な皮膚の変形やdiffuseやspecularといった反射の分離を要求しない上に、複数の画像も要求しない。Caoらの手法では表情をいくつか与える必要があり、その情報から口内や目の情報を取得しているが、本手法は、正面写真一枚から口内や目の動きも再現可能である。
[8] Face Transfer with Multilinear Models, Vlasic et al., (2005)
Vlasic et al. (2005)は、identityとexpressionの相関関係を考慮した表情生成を可能にした一方、トレーニング時に使用した多くの人の表情を線形に補間するため、high frequency detailを失ってしまう。Jiemenezら[9]のクオリティがあれば問題ないが、一体のモデルを作成するのに一つ一つの表情を取得する必要があり、非常に大変な作業である。
[9] A Practical Appearance Model for Dynamic Facial Color, Jimenez et al. (2010)
提案手法

無表情画像に対して、morphable modelをフィッティングし、そのidentityを保ちながら、別の表情を生成し、無表情のマスク、無表情を変形した際のマスク、そして、normalとdepth情報を元に、表情変化後のもっともらしい表情のテクスチャを生成する。その後、キー表情分のテクスチャを作り、実時間にブレンドすることで表情アニメーションを再現。
Dynamic Texture Synthesis

基本的には、提案手法の概要でも話している通り、masked neutral imageとdeformed neutral + gaze、expression(depth + normal)の3つの情報からシワなどの詳細の載った表情のテクスチャを作るところが鍵となる。その生成部分は、以前紹介したHuynhらの論文でも使っていたIsolaらのImage-to-Image Translation [ 論文 ]を用いている。

Bulding FACS Textures
一度学習してしまえば、入力画像に親しい表情を(動画であればフレームごとに)推定することは可能であるが、(毎フレーム)その処理をするには負荷がかかりすぎる上に、ハイエンドのGPUが必要となるため、モバイルでの実装は困難になる。そこで、一度、ハイエンドのGPUでリアルタイム用の表情テクスチャを表情個分作っておけば、実時間でその画像をブレンドすることでモバイルでの表現も可能になる。

それを実現する際に、すべてのUV空間をブレンドすることも実質可能であるが、表情の細かい部分が僅かに変わってしていたりしてアーティファクトになってしまうため、表情ごとのUV activationマスクというものを考慮して計算を行う。UV activationマスクは、UV空間の頂点IDから、無表情と表情付きの3D頂点位置の誤差を計算し、その誤差に応じて、UV頂点に色付けをしていく。その後、Gaussian Blurをかけると、接続していない箇所がきちんと消えていいらしい。
この手法は理論的には正しいが、何十個もある表情にすべて作るためにアクターに各表情を作ってもらうのも難しいため、簡単にできる表情K個(論文では6個)だけ作るようだ。実時間での表情テクスチャのブレンディングはpixel shaderで行っているらしい。
その他(目や口)
- 目に関しては、20個のテクスチャを事前に用意して、gaze trackerの結果に応じて、nearest neighborで近い目のテクスチャを持ってきて、compositeしているらしい。
- これは目の色パターンを20個用意しているわけではなく、目の方向のパターンを20個用意しているっぽい。
- 口は、300パターンのテクスチャを用意。口のブレンドは、nearest neighborではなく、以下の論文を使っているそう。
- 具体的には、nearest neighborで見つけた50個の口内テクスチャをweighted median blendingという手法でblendしている。(pixel shaderで実装)
youtu.be Synthesizing Obama: Learning Lip Sync from Audio, Suwajanakorn et al., SIGGRAPH 2017 [ 論文 ]
データセットに関して
- メモ程度

データセットリスト (論文より)
結果



Limitation

- 入力の顔向きが正面じゃない
- 顔のシャドウ
- 舌
- 手などのオクルージョン
- 加えて、歯がかけている人は、正しい歯になってしまったりする様子。
雑感
- 比較がたくさんあって内容盛り沢山な論文。やってるプロセスは理にかなっている。
- Image-based avatarなので、正面画像で生成したとしても、トラッキング中に横向いて口を開いたりすると口内がおかしい感じに見えるんじゃないかなと予想。口を大きく開いて、横を向いている画像が論文中に見当たらなかったので。
- 以下の論文みたいに目や口のジオメトリを用意したほうが、ゲームエンジンなどでは組み込みやすいかな。
論文紹介: Learning Formation of Physically-Based Face Attributes
こんにちは。iwanao731です。2日連続の投稿です。表情生成のあたりを知りたくなったので、最近よく調べています。表情の研究って技術的にはやることたくさんあるし、コロナ禍の中でリモートでのコミュニケーションが大事になってくるというので、今後非常に重要になってくる技術であります。ですが、個人的にそれ以上の用途が浮かばないというか、ワクワクするような利用用途みたいなところがいまいち思い浮かばないし、結構どこのラボも同じようなモチベーションでやっているので、全然違う視点のアプリケーションや研究を見つけたいな、という気持ちがあったりはします。まぁアイデアはないんですが。。。
概要
Learning Formation of Physically-Based Face Attributes
Li et al., CVPR 2020
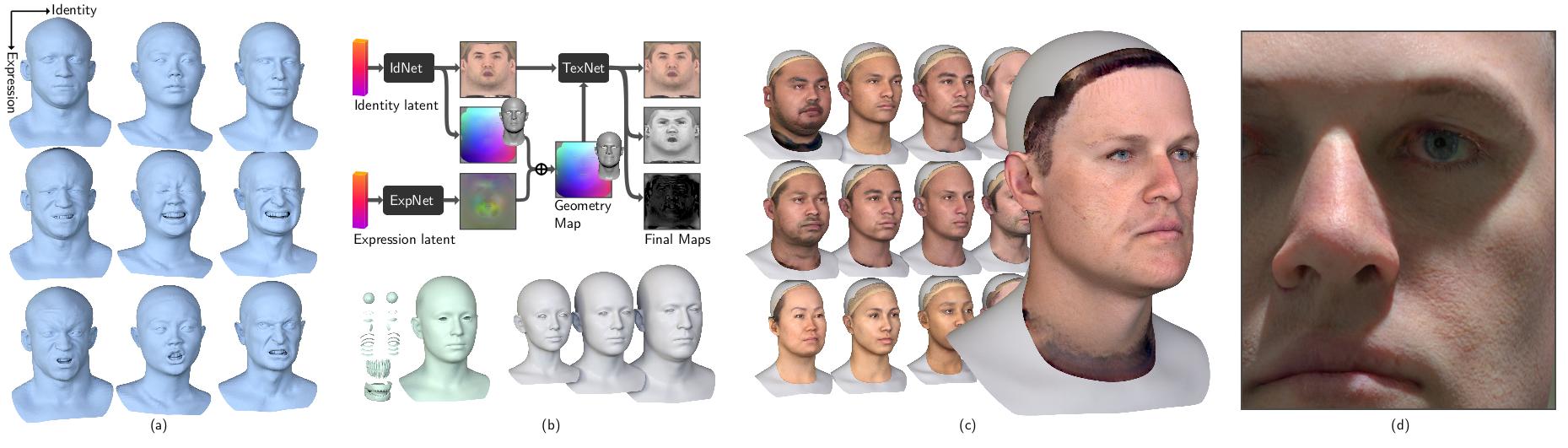
High FidelityなGenerative Face(Head) modelの提案。GANを使い、FaceのIdentityや表情、mid/high frequencyなgeometry、albedo、specularといったリアルなデジタルアバターに必要なデータを制御可能。何千パターンものHigh FidelityなHeadを生成することができる。
関連研究
ハイクオリティな顔のモデルを作るのは非常に手間がかかるため、実際に存在する/した人であれば過去の写真等から顔の形状を再現できたりすれば理想である。
それ以外に、実際に存在しない人であっても、パラメータ調整によって色んなバリエーションの高精細な表情モデルができたらそれも面白いかもしれない。1999年のSIGGRAPHで発表された3D Morphable Model (3DMM) はまさにそのコンセプトを実現した最初の研究である。3DMMは、様々なスキャンした顔の形状とテクスチャをPCAで圧縮し、次元を変えるだけで様々な人の顔をパラメトリックに生成することを可能にした。そんなMorphableモデルの過去、現在、未来をまとめた論文があるようなので気になる方はそちらを見てみるのも良いかもしれない。 [ 論文 ]
顔の領域だけだったMorphable Modelから、頭部のパラメトリックモデルを実現したFLAMEという論文は、表情やIdentityだけでなく、首の回転などの要素もすべてパラメトリックにした。こちらのモデルではテクスチャはついておらず、顔の詳細な情報も考慮はしていない。
毛穴レベルの形状は再現できなかったり、近年の物理ベースレンダリングのためのテクスチャアセットがなかったりして、過去のパラメトリックな顔モデルは高精細なデジタルアバター表現には不十分であった。もちろんLight Stageを使ってクオリティの高いテクスチャや形状を得ることは可能であるが、コストも時間もかかってしまうため、Morphable Modelの高解像度版を作りたい、というのが本論文の目的に親しい。
近年だとHao Liのグループが写真一枚から高精度な表情をモデリングする技術を発表している。これらの論文は、写真一枚から、テクスチャのalbedoを皮膚レベルにアップサンプリングしたり、mid/highレベルのgeometry mapを生成したり、specular mapを生成したりとデジタルアター生成技術に大きな貢献を果たしている。
これらの手法のlimitationを敢えて挙げるとするならば、写真一枚を入力しないとモデルが生成できない点にある。本論文では、外部のパラメータを与えるだけで様々なバリエーションのアバターを生成してくれる技術をGANを応用することによって実現している。
提案手法

本論文では、入力として、IdentityとExpression情報が必要となる。IdentityからUV空間のテクスチャとジオメトリ情報を生成し、Expressionからは、blendshapeのoffsetを生成する。IdentityのGeometryにoffsetを足すことによって表情を作り、一方でアップアンプリングしたテクスチャをTexture Inferenceに送ることで1Kのalbedo, specular, geometry mapが生成される。そのmapをExpression Geometryに加えることで高精細なアバターを生成する。
顔モデル

高精細なアバター生成に必要なモデル情報が含まれている。
使用したデータセット
- Light Stageで撮影した18-67歳の男女。女性34名, 男性45名の計79名。各アクターから40個のFACのうち、選定した26個の表情を取得。(albedo,geometry,specular, expression)
- triplegangersというサイトから選定した99名のアクター。各アクターごとに表情は20個。(上記に比べ、specularのtextureなし)
個人の顔モデリング
顔の形状とテクスチャ(albedo)は相関関係があるという仮定のもと、Style-GAN Architectureを用いて、高精細かつ制御可能な顔を学習する。
Identity情報からalbedoのテクスチャと頂点位置情報(geometry)のテクスチャを生成。整合性を保つために、以下の3つのdiscriminatorを用意している。

- 生成したtextureがGround Truthに近いか。
- 生成したgeometryがGround Truthに近いか。
- 生成したtextureとgeometryの組み合わせがGround Truthに近いか。
表情のモデリング
表情の学習を簡易化するために、geometry情報をUV空間のテクスチャ情報に落とし込み、neutral表情との差分をoffsetとしてテクスチャを生成している。Identity Networkと同様にStyle-GAN Architectureを使用。Networkへの入力として、FACSの表情25個に対するブレンドシェイプウェイトを使用。

- R_expでは、生成されたoffset textureからblend weightを推定し、またそのウェイトから生成するようになっている。
- D_expはGround Truthに近いかどうか。
高解像度化
高解像度化に関しては、Yamaguchiらと同様の手法を利用。彼らがalbedoのみを入力としているのに対し、geometry mapを使用。Huynhらの手法と同様にmid/high frequency textureを生成し、upsampling [ 論文 ]。
結果


他手法に比べて、非常にオリジナルに近い形状が得られている。この結果を得るために、入力画像のLatent spaceを知るための技術 [ 論文 ]を利用。また、Geometryの形状は、Laplacian morphingを利用。

ドメインが同じであれば、それに基づいた詳細モデルを生成可能。

表情の補間も可能。表情のパラメータが0.0-1.0じゃないので、従来のblendshapeのウェイトとはまた異なるルールが必要かもしれない。
今後の課題
- IdentityとExpressionがそれぞれ独立しているので、個性を考慮した表情を作ることが難しい上に、生成されたExpression offset textureはidentity expressionのmiddle frequencyが含まれていない。
- 今後は、この相関関係を考慮することが課題。
- 表情生成に、ニューラルネットワークのArchitextureと3D geometryのresamplingが必要になるので、facialのretargetが未だできていない。
- 入力画像からIdentityを推定するために、differentiable rendererのような仕組みが必要。
- ライティングによって結果が変わるかもしれない。
雑感
- 写真一枚からアバター生成といったアプリケーション用途ではまだ利用は難しい印象。
- たくさんそれっぽいアバターを作るという話だったら色々と使いやすそう。
- 表情のリターゲットもまだ制御が難しそうなのと、個人の顔とその表情の相関関係を考慮するのは今後必須になってきそう。
論文紹介: Mesoscopic Facial Geometry Inference Using Deep Neural Networks
こんにちわ、iwanao731です。最近緊急事態宣言が解除され、少しずつですが日常が戻りつつあります。世間では、「ニューノーマル」や「ウィズコロナ」と言ったワードが示すように、これからの生活は今までと異なるような見解が多いですが、案外今まで通りの日常に戻ることもあり得るんじゃないかな、と思えてきます。緊急事態宣言が解除されたと同時に在宅勤務も終わり、出社することになりました。今週から出社しているのですが、やはり移動時間が長いのでもったいないなという気持ちが芽生えてきます。往復で1.5hなので、一週間で7.5h。もはや一日の就業時間に当たるわけですよね。非常にもったいない!
そう、先週ホロデヒというイベントが開催されまして、それで登壇してました。最近Volumetric Videoという技術が気になっておりまして、その内容についてお話させていただきました。アーカイブが出ているので良かったら見てください。
無事発表終わりました!聞いていただいた方々ありがとうございました! #ホロデヒ https://t.co/viQTUTFr1U
— Naoya Iwamoto (@iwanao731) 2020年5月23日
概要
Mesoscopic Facial Geometry Inference Using Deep Neural Networks
Huynh et al., CVPR 2016
[ 論文 ]
顔のしわや毛穴といった詳細の情報を、顔を3Dスキャンして取得したテクスチャからディスプレイスメントマップとして推定する技術。テクスチャからMed-frequencyとHigh-frequencyの2つに分解し、それぞれで4Kサイズにupsamplingし、合成。
system pipeline (論文より)

関連研究
顔の形状とテクスチャがセットになったMorphable modelの登場によって、写真一枚からでも顔を復元できるようになった一方で、まだまだ皮膚の毛穴やシワといった詳細な情報は考慮できていません。最近になって少しずつMorphable modelにどう詳細な情報をつけるかといった論文が出始めてきていますがまだまだ課題となっています。当時だと、Saito et al (2015)の論文が顔のテクスチャを高解像度にするというので話題になっていました。
youtu.be [1] Photorealistic Facial Texture Inference Using Deep Neural Networks, CVPR 2017
一方で、顔のジオメトリの情報に関しては未考慮であったため、どうキャプチャ後のモデルに皮膚レベルの詳細を足すかといった課題に取り組んだのがこの論文です。皮膚は表面化散乱が起きるので普通のキャプチャシステムで詳細なジオメトリを取るのは案外難しくて、その詳細を取るためにShape From Shadingという色んなアングルからライトを当てて、それによって生じる陰の情報から詳細な形状を復元するというのが主なキャプチャ方法になっています。そんな中でかなり高クオリティなキャプチャを達成したのが、フェイシャルの高精度な表情キャプチャ関連で必ず出てくるBeelerらの論文との比較が多めにあります。10年程度経つ今見てもかなりクオリティが高いです。
youtu.be [2] High-Quality Passive Facial Performance Capture using Anchor Frames, SIGGRAPH 2011
Light Stageを使えば、非常に高解像度のdisplacement mapも撮れるには撮れるのですが、High speedカメラが必要という理由でdefenseしてます。
youtu.be [3] Multiview Face Capture using Polarized Spherical Gradient Illumination, SIGGRAPH 2011
実時間で取得した表情にシワを足そう、という論文が顔の研究でおなじみCaoらによって研究されています。彼らの研究ではシワレベルは再現できても毛穴レベルは再現できていないということで、今回の論文では実時間ではないものの、クオリティはCaoらよりも高いということが言えます。今回の論文ではpore(毛穴)-levelとかmesoscopic(ミクロの)というワードがよく出てきます。
youtu.be [4] Real-time high-fidelity facial performance capture, SIGGRAPH 2015
もう割と関連研究でお腹いっぱいというか、関連研究とどう差別化しているか、っていうところが割と研究で重要な気がしたので、これからそのあたりをメインに書いていくかもしれないですね。
提案手法
3Dのジオメトリを3Dの情報としてニューラルネットワークでトレーニングするPointNetという論文があったりするのですが、それだとメモリを大量に使用してしまうということで、彼らの提案手法では、2Dのテクスチャ空間でディスプレイスメントマップとしてエンコードするというのがポイントになっています。テクスチャ空間に落とし込むと、3次元情報よりも軽く、異なる人物間のジオメトリの個性をencapsulate(要約?)できるというのが優位性になっているようです。もちろんCNNで学習しやすいというメリットもあります。
本論文では、displacement情報からmediumとhigh frequencyに分けた後、それぞれでenhanceするサブネットワークを設けていて、実際にLight Stageから取得した情報を正解としてトレーニングしているようです。Light Stageから取得したdisplacement mapをGaussian Filterをかけてなましたものをmed-frequencyとし、All- med = high frequencyとして取得していて、それを学習している様子。データは328人分からトレーニングしているようです。
TextureからDisplacement Mapに変換するところは、Image-to-Image Translation with Conditional Adversarial Networks [ 論文 ]が参考になっているそう。
Image-to-Image Translation with Conditional Adversarial Networks
結果
結果の比較。(論文より) 結果2 (論文より)


Beelerらの結果に劣らない結果が得られている。
今後の課題や展望
- 学習のためのdisplacement mapはsubject(被験者)ごとにUVを合わせる必要がある。
- Saitoらのalbedoを高解像度にする手法と組み合わせれば、albedoとdisplacement mapという2つの高解像度テクスチャが得られる。
- 上記のようなmorphable modelベースの手法と組み合わせるのもあり。
雑感 - albedoとdisplacementといったらあとはspecularですね。次回は、1枚の写真からalbedoもdisplacementも、そしてspecularも推定してしまう技術論文を紹介したいと思います。
- High-Fidelity Facial Reflectance and Geometry Inference From an Unconstrained Image [ 論文 ]
論文紹介: Fusion4D: Real-time Performance Capture of Challenging Scenes
コロナ、大変ですね。皆さんは家でどのように過ごしていますでしょうか。僕は、家でひたすら論文を読んだり、実装をしたり、それ以外は時々散歩にでかけたり、あとは料理をしたりですね。餃子やタコスパーティ、あとはたこ焼き器を買ったのでタコパなんかもしてなるべく楽しく過ごせるように工夫しています。ちょうど一昨年、昨年と、ハワイに行ったり、LA(Cochella)に行っていた時期なので、海外に行けないのはとても残念ですが、僕よりも大変な状況な方はきっとたくさんいると思うし、僕らは僕らはなるべく被害が拡大しないよう、なるべく家で色々と工夫しながら過ごしていければいいな、と思います。いや、しかし、このVolumetric Videoの分野は非常に分野として活発なので、次から次へと論文が出てきて大変ですね。このままGWまでしばらく論文を読んでいく事になりそうです。
そういえば、落合陽一氏がNewspicのWeeklyOchiaiという番組で、とても納得することを言っていました。今後、社会に対してデジタルの付加価値をどう提供できるでしょう。
デジタルの付加価値を作る難しさは確実にあるけど、唯一PerfumeのCochellaライブは映像で見た方がよかったと感じれる体験だった。リアルを拡張したフィジカルなデジタル体験はコロナをきっかけとして広がっていきそう。 https://t.co/5DqawJU3PH
— Naoya Iwamoto (@iwanao731) 2020年4月18日
今、僕ができることは、Volumetric Videoの技術を自身でより理解し、言語化し、伝え、実装し、社会に実現し、普及させていくこと。今は、そういったことができればと思っていて、その準備期間っていう感じです。準備だけで一生を終えるかもしれませんが笑
Volumetric Videoのデータとその撮影画像、各カメラパラメータを使って、Blenderで可視化してみた。 #blender #b3d 使用したデータはこちら。https://t.co/xSSQ8Ylv8X pic.twitter.com/5nr5GCxQQl
— Naoya Iwamoto (@iwanao731) 2020年4月18日
概要
Fusion4D: Real-time Performance Capture of Challenging Scenes
Dou et al., SIGGRAPH 2016
[ 論文 ]
単一のRGBDカメラを使用した実時間パフォーマンスキャプチャ技術に関する研究。従来難しかったダイナミックな動きにも対応し、安定したトラッキングが実現できる。
過去の研究との差異
多視点のRGBDカメラで静的な物体のスキャンを実現したKinectFusionの応用として出たDynamicFusion[1] は、動的な物体のスキャンも可能にした一方、その動きは非常にゆっくりでないと破綻してしまう問題があった。加えて、トポロジーが変わってしまうようなシーン(例えば、手が体とくっついてしまった場合に、そこから抜け出せなくなる)に対応できない問題もあった。
[1] DynamicFusion: Reconstruction and Tracking of Non-rigid Scenes in Real-Time, Newcombe et al., CVPR 2015
また、実時間で身体をキャプチャする関連研究として、体の部位に特化したテンプレートモデルを使用する研究[2]も登場したが、いずれも対象物体が決まっており、例えば赤ん坊とか犬といった異なる動的な形状には対応していないことが欠点だった。
[2] Real-Time Non-Rigid Reconstruction Using an RGB-D Camera, Zollhofer et al., SIGGRAPH 2014
そういった背景から、対象物体を限定せず、実時間で、かつダイナミックな動きにも対応した、というのが論文の特徴となっている。
提案手法

・Key Volumeによって、ノイズの多いデプス情報を累積しながらスムーズにすると共に、極端なトポロジーの変化にも対応。 ・Closet Point [1][2]ではなく、Correspondence Fieldによって、早い動作にもロバストな対応点検出を実現 ・Data volumeに累積した現在のモデルをKey VolumeをWarp、そしてResampleすることで統合。それにより、新しく取得したデータに対しての応答がとても早い。 ([1]では、現在のkey volumeを変形させるDeformation Fieldの推定により、表面のdetailを保持し、Key Frameに統合。)
TBD
とりあえず今日はここまで。
論文紹介: Detailed Full-Body Reconstructions of Moving People from Monocular RGB-D Sequences
こんにちは。2日連続の投稿です。最近Blenderをやっているという話をしたと思うのですが、そのときにやっていたチュートリアルの講師のBlender Guruさん(たしかAndrewとかそういった感じ)さんのやつをやっていました。
でその人の講演みたいなものを聞いて、クオリティよりも量が大事だ、と言っていたので、クオリティはさておき、とりあえずざっくり読んだものをまとめる空間を作っておこうと思って、今日も続けます。
概要
Detailed Full-Body Reconstructions of Moving People from Monocular RGB-D Sequences, ICCV 2015
Kinectを用いたRGBDデータでキャプチャされた人体の形状をパラメトリックモデルを使用してフィッティングした論文。 Coarse-Fineモデルを作ることによって、全体的なフィッティングから詳細の形状まで反映できるようにした。ある程度近付けたあとはDisplacement mapを使って視覚的に非常に近い形状を示すことができている。
・coarse-fineメッシュを考慮した次元圧縮(PCA)した全身形状だけでなく、頭部に特化したPCAの次元を用意することで頭部領域のフィッティングも可能にした。(second PCA model for head identity deformations)。PCAの次元は全身も頭部も上位20個のみを用意。それ以上増やすと最適化が難しくなるそう。 全身をそれなりに粗いメッシュの状態で全身PCAのパラメータをフィッティングした後、Fine meshに切り替えて、更に頭部PCAで顔形状のフィッティングをすると本人に近い形状に。その形状に、2Kのテクスチャと0.5Kのディスプレイスメントマップを加えれば出来上がり。
他研究との差異
三次元形状復元に関する研究は、モデルフリー(対象物体を定めない)とモデルベース(対象物体が決まっている)に分けられる。
モデルフリー
特に人体の復元に関しては、人が完全に静止することが難しかったりするのするため、KinectFusionのようなモデルフリーのスキャンのような場合は、撮影者と対象者は別々で対象者は静止してないといけなかったりと非常に手間である。その後、その応用となるDynamicFusionが登場したが、非常にゆっくりとした動きでないとトラッキングできない制約があった。2015年頃は、まだ実時間での非剛体形状の高速なトラッキングを実現している論文はほとんどなかったと言える。
モデルベース
モデルベースの手法に関しては、パラメトリックなモデルを使用することで、様々なポーズの正確なフィッティングを実現しつつある一方、やはりメッシュの解像度が荒いため、高精細(high frequency)な情報を失ってしまう問題点があった。ここ最近はパラメトリックなモデルに対して、詳細な情報を加える系論文も増えてきました。また、この頃の研究結果の多くはテクスチャの解像度がとても低く、高精細なテクスチャをどう取得するかが大きな課題だった。
感想
この論文でいいところは、progressively adding detailっていうところですかね〜。他の論文でもあると思うんですが、キャプチャすればするほど形状やテクスチャの精度が上がっていくのいいですね。当たり前っぽく聞こえるかもしれないのですが、いくらキャプチャし続けても一向に形状がrefineされない論文って多いですよね。下に示したEPFLのチームが2013年に出したFacial Trackingの論文とかも、テクスチャはないですが、どんどんフィッティングされていく様子が見ていて楽しいですよね。
この論文の優れたところは、精度の評価を非常に丁寧にやっているところだと思う。よくある関連研究だと、特別な設備でスキャンした形状を正解形状としたときの誤差や他の手法で復元した形状の誤差との比較はよくあるが、例えば、同じ人の異なる動きを通じて、どのくらい誤差が生じたかといったところは非常に有益な情報であるし、特別なキャプチャスペースではなく、被験者の自宅での復元結果、テクスチャの精度を評価のためのスタンプを体に押しているところ、加えてKinectのジョイント推定だとうまくトラッキングできないところを本手法だときちんと皮膚レベルまで(二次動作)取得でき散るといったことも非常に説得性がある。
なんか読み返すと自分の喋り方が非常に不安定w
論文紹介: Motion2fusion: real-time volumetric performance capture
久しぶりの投稿です。昨年デジハリを卒業した後は、忙しかったこともあり、その反動で気が抜けたような年になってしまいました。何もできなかったなぁと反省してたりします。そういうこと以外には同棲なんかを始めたりして、自分の時間を減った一方で、また別に楽しむ時間というのは増えた気もします。 仕事的には、2018年頃にやった仕事が会社で賞をもらって、様々な賞をもらったり、挙句には本社のSNSに挙げてもらえたりして、非常にありがたい年だったと思います。
Meet the creator of the 3D live maker, an #AR application on Huawei’s #Mate20Pro – Iwamoto Naoya. What’s life like for this senior researcher? Watch and find out. #WhoAreWe #innovation pic.twitter.com/LChGAkxpaD
— Huawei (@Huawei) 2019年8月27日
最近は、もうコロナで大変です。オフィスへの通勤も在宅になり、日常が一気に変わりました。去年の今頃はCochellaという世界最大興行収入?のフェスに行っていて最高の時間を過ごしておりましたが、最近は粛々と家で仕事などをしています。基本外出禁止ということなので、家で過ごす時間が増え、最近はワンピースを全館読むなど暇の極みみたいなことをして楽しんでいます。
しばらく時間は空いてしまいましたが、これまで全く論文を読んでいなかったというわけではなく、新しい知識を入れるための勉強、というか主に論文を読んで基礎知識をつけていたりしました。しばらく前ですが、アメリカの経済制裁によって社内の3DツールとしてMayaが使えなくなり、Blenderに移行し、一通り、Blenderのチュートリアルをやった頃に、Volumetric Video(VV)という分野?にハマり、そのあたりをずっと調べていました。最近になってちょっとずつこのVVシステムの実装のための基礎技術開発なんかを進めています。
前置きが長くなりましたが、論文の中身に入っていきたいと思います。
概要
Motion2fusion: real-time volumetric performance capture [ 論文 ]
実時間で非常に高精度かつ高速な動きのパフォーマンスキャプチャを実現した論文。最近のナウいワードだと、Volumetric VideoやVolumetric Captureなんて呼ばれていたりします。
論文のオリジナリティ
- 従来研究で問題だった形状が滑ってしまう問題に対して、新たなNon Rigid Alignment(非剛体位置合わせ)手法を提案
- 従来の位置合わせ手法で非常に重い行列計算だった箇所を機械学習手法に置き換えることによって、フレーム間の対応を高速に計算
- フレーム間によって変化するトポロジーを正確に捉え、それに合わせた正しい対応点抽出を実現
関連研究
僕の中の記憶だと、だいたい2008年くらいから全身をキャプチャする研究は盛んにおこなわれてきていますが、2015年にMicrosoftが出した論文によって、その熱が加速してきました。Microsoftの論文では非常にクオリティの高い全身復元動画(Volumetric Video)のキャプチャを可能にしましたが、実時間でその精度を再現することはまだ困難な状況でした。一方で、2011年ごろに登場したKinectFusionという論文では、一台のKinectを使用して、様々なアングルから対象物体をRGBD撮影することで、静的な物体に限り、3次元形状をきれいに復元することを可能にしました。その後登場したDynamicFusion等の論文によって実時間に動的な物体の形状を取得することも可能になりました。しかし、素早い動作に対してはメッシュが破綻してしまうという問題点がありました。また[ DoubleFusion ]等で行われているような、人体のテンプレートモデルといった事前情報を使わず、基本的には様々な動的物体を撮影可能ということで、個人的に非常に注目している論文です。
ここで紹介した論文等は今後別記事にて紹介できればと思っています。そういった記事を参照することでこの分野への相互的な理解も増えていくと思います。
提案手法

入力はRGBDが入力となり、そのポイントクラウドから、Deformation Graph(DG)を作成し、フレーム間のDG間の対応関係をSpectral Embedding Algorithmを利用して別空間へと投影することで、互いの距離をロバストに検出することを可能にしました。
対応点が見つかった後、Embedded Deformation (ED)と呼ばれる手法を使って前フレームの形状を次フレームに変形させていきます。その後は、Detail layerやAtlas texturingを使って、よりdenseな形状の取得を実現しています。

今日はいったん力尽きたのでまた後日更新します。
論文紹介: Neural Kinematic Networks for Unsupervised Motion Retargetting
令和になりましたね!特に何か大きく変わるわけじゃないですが、婚約した友人が何人かいました。そろそろ結婚を考える時期でしょうか。 GW中はというと、どこに行っても混んでいるので近所のカフェで論文を読んだりして過ごしていました。 仕事ではなく趣味なんですが、本当に他人にはわかってもらえない趣味ですよね。 内容が全くわからないとかなり辛いのですが、わからないことがわかるようになるってやっぱり楽しいですよね。
そんなこんなでGW中に読んだ論文なんかをここに紹介していきたいと思っているわけですが、さらっと一通り読んでみても いざここにまとめるとなるとうまくまとまらないですよね。書くのってけっこう時間がかかる。。。 ですが、あとで眺めたり、一旦まとめたりすると記憶の手助けになるので続けてやっていきたいと思ってます。 取り上げる論文は単純に最近興味ある関連のものです。今はちょうどモーション系に興味があります。 今更気づいたのですが、小話があってからのCGに関する内容のブログってちょっと手抜きOpenGLっぽい。
概要
Neural Kinematic Networks for Unsupervised Motion Retargetting
[ プロジェクトページ ] [ 論文 ] [ 補足資料 ] [ コード ] [ スライド ]
従来のモーションリターゲット手法は手作業で設計された制約に基づいた繰り返し最適化(iterative optimization)を用いるものが主であったが、本研究では、Reccurent Neural Networkを用いて、正解データを用意せずともシングルパスでモーションリターゲットを行える手法を提案。近年のDeep Learningを用いた人体動作に関する研究では関節の位置をそのまま使用するものが多いが、本研究では関節の回転情報を出力するため、Forward Kinematicsによってキャラクタの骨の構造を考慮した(ボーンの長さが不変な)アニメーションを生成できる。提案手法によって、キャラクタ間の身体構造の違い(背の高さや腕の長さなど)からくるリターゲットの不具合を解消し、キャラクタAの動きをキャラクタBに自然に適用することを可能にした。
提案手法
モーションを生成するパート
Neural Kinematic Networks
RNNを使用して、キャラクタAのモーションからキャラクタBのモーションを生成するフレームワーク。 各時間tでのルートジョイントから各関節への相対位置pとルートジョイントの速度vを入力とし、RNNのencoderでencodeし、それにキャラクタBのニュートラルポーズ(Tポーズ)を入力し、decodeすることでキャラクタBの各ジョイントの角度を出力。Forward Kinematicsを用いることで、キャラクタBのモーションを再構成。
モーションを学習するパート
Adversarial Cycle Consistency Framework
通常、キャラクタのモーションリターゲットをトレーニングするには、体型の異なるキャラクタに同じ動きをさせたぺアデータセットを大量に用意しなければいけない。それがモーションリターゲットを未だ困難にしているが、本手法では、Adversarial cycle consistency frameworkによって、ペアのデータを用意せずとも自然なリターゲットを実現する。本フレームワークには、以下の4つのlossが提案されている。
Adversal loss
- 入力したキャラクタAのモーションと、生成されたキャラクタBのモーションが近いかどうかを判別するobjective。入力及び生成モーションの、フレーム間のジョイントの差異及びルートジョイントの速度の差異を計算。
Cycle consistency loss
- 生成されたキャラクタBのモーションを再びキャラクタAにリターゲットし、最初の入力のキャラクタAのモーションとの差異を計算する。
Twist loss
- 上記2つのobjectiveでは、過度なジョイントの回転が生まれてしまったため、ジョイントのtwistのobjectiveを用意。ボーンと並行の軸に対しての回転を考慮。
Smoothing loss
- フレーム間の連続性を考慮するobjectiveを用意。
結果
Mixiamoのモーションを使用した場合
- Mixiamoのキャラクタ7体(22個のジョイント)と1646 のトレーニングシーケンスを使用して実験を行った。各objectiveのそれぞれを外したものをすべてのものを比較し精度を評価。なお、ground truthはMixiamoで制作。提案手法では、ボーンの長さをきちんと考慮したモーションリターゲットを実現した。
- Cycle consistencyは、手先足先の位置を回帰することを防ぐため、身長の違いによる手の位置の違い等も考慮することができた。
- Adversarial objectiveは、自然なモーションを生成することを可能にした。
- Twist lossは、ボーンの過度な回転を防いだ
Human 3.6Mのデータセットで取得したモーションを使用した場合
- 関節数が17個のため、長さ0のジョイントを増やし、22個でMixiamoの関節構造と同じにした。
- こちらも自然な動きを生成することができた。
今後の課題
ジョイントの個数がfixになってしまう。
- 手足、足先で評価できる手法の提案が必要?
物理の考慮
- リターゲット先のキャラクタの体重など、キャラクタのPhysics要素の考慮が必要。
2次元ジョイント位置の入力
- 現状、三次元関節位置を入力する必要があるが、今後、二次元に対応するとなお良い。