論文紹介: Semantic Deep Face Models
お久しぶりです.久々に論文をまとめようと思ってます. なんと11月はじめにコロナ陽性になりまして,ホテル療養や自宅隔離をしていたらあっという間に11月が終わりそうです. その間にフロンターレが優勝したり,キングダムを全巻読んだり,そして論文を読んだりして,なんだかんだで充実した11月でした. 今年ももうすぐ終わりですね.来年は顔だけじゃなくて,モーション系の知識も蓄えながら,でぃーぷらーにんぐの実装もしていこうかな,なんて思ってます.
概要
Semantic Deep Face Models
関連研究
近年,Morphable Modelを利用した顔関連論文が後をたたない一方で,Morphable Modelの欠点を指摘して,独自にデータベースを作る研究なんかも増えてきていますね.Morphable Modelの欠点は何かというと,IdentityとExpressionが完全に切り分けられていないことです.例えば,無表情で目が細い人がいたときに,IdentityとExpressionをあわせて推定してしまうと,対象人物が目を細めている表情として推定されてしまう恐れがあるということです.なので,IdentityとExpressionを分解する,Disuntangleするという研究が近年で注目されてきています.
今回の研究はDisney Researchによる研究なのですが,Disney Research研究あるあるのBeelerらのスキャニング技術を今回も使っています.しかし,従来彼らがやってきた変形系の話ではなく,顔のパラメトリックモデルを作るという研究を打ち出してきたので,流れに乗ってきたなと僕は個人的に思いました.
この手の研究は既に(といっても去年くらいからだが)Hao Liの研究チームもLight Stageで取得したデータを活用して,更に口内や眼球といったパーツの情報も分解したパラメトリックモデルを公開して,表情もFACSベースだったりするのでかなり有用なデータになっています.こちらのデータは[ ICT-FaceKit ]としてリリースされました. iwanao731.hatenablog.com
そして,近日そのHao Liのグループの最新論文についてもまとめようと思っているのですが,その論文もIdentityとExpressionをどう切り分けるかという話なのでもろかぶりですね!
提案手法
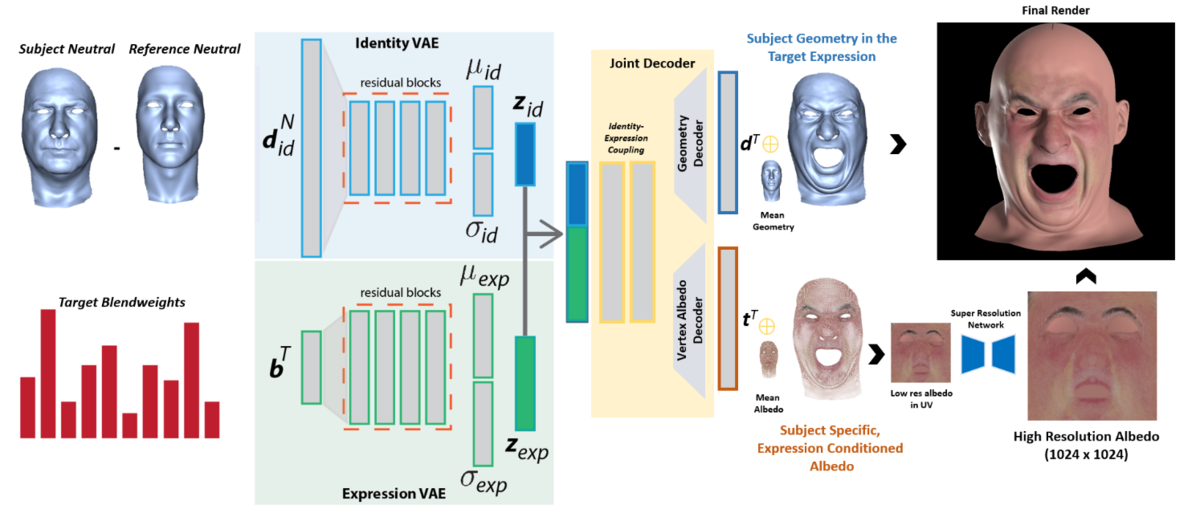
まず,データセットとして,Beelerらのスキャナーを使った224人x24種類の表情と17人分のフェイシャルワークアウト(かっこいい呼び方)データを取得します.そしてある人の表情24個(位置合わせ済み)をブレンドシェイプのターゲットとして登録し,その人のリトポ済みのワークアウトメッシュデータをターゲットとして,ブレンドシェイプの係数を推定します.そして,こちらの図の入力上部が対象者の無表情メッシュ,下部が推定されたブレンドウェイトとして,それぞれIdentity VAEとExpression VAEでlatent spaceに変換します.そして最後にJoint Decoderを使ってメッシュに戻すのですが,それとワークアウトによってキャプチャしたメッシュとのLossをとってモデル化していく,といったプロセスです.このJoint Decoderが,Identity-based expressionを作るという意味合いで今回の主な提案技術となっています.
結果
このモデルを使うと,例えば,無表情から笑顔になるといった表情変化も,線形の場合とは異なり,最初に笑った表情になってから口が開いていくといった非線形的なアニメーションを実現できるそうです.

あとは,Expression固定でIdentityを変化した場合も,人による表情の違いが再現できていると言えそうです.

ランドマークからブレンドウェイトの推定を行うことで,表情トラッキングを実現するスキームも確立されていました.
Limitation
ここはあまり理解できなかったのですが,与えられたブレンドシェイプ係数に対して,意味の持った形状を生成できる保証がない,と述べられています.これはおそらく,見た目的に形状が破綻したとしても,形状が破綻しているかどうかが計算上判別がつかない,といったことだと思います.通常であればアーティストが設計したブレンドシェイプターゲットがあって,0-1の値が入るのでたいてい表情が崩れることはないのですが,それでも組み合わせによっては大いにおかしくなるため,それと同様の問題があるといえるでしょう.
結論
画像からランドマークを検出してexpressionを推定するスキームはあったが,Identityを画像から推定するスキームが示されていなかったのが気になる.以前のHao Liの論文でもIdentityをlatent spaceでいじれるけど,そもそもそのlatent spaceのパラメータをどうやって推定するのかというところが気になるところであります.