論文紹介: MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentanglement
こんにちは、iwanao731です。
コロナ禍二年目ですが、相変わらず変わらない生活が続いていますね。第一回の緊急事態宣言に比べて飲食店での酒類の提供ができなくなってしまったので、遠くにも行ってはいけないし、外で飲むこともできない、といった難しい生活。そんな中で趣味の川崎フロンターレのサッカー観戦(DAZN)や近所のワインショップで買った自然派ワインで何とか楽しく過ごせています。
会社の仕事は今まで敬遠していたDeep Learningに取り組み始め、CG研究を始めてから10年という節目でもあるため、自分の中で第二章が始まろうとしているといった感じです。やるテーマがアニメーションやリギングに関することであることには変わりないですが、自分の中で表現できるスキルを広げていければ、自分のアイデアをカタチにすることがより多くできてくると思っています。なかなかDeep Learningの研究には慣れないですが、サンプルプログラムを参考にしつつ、自分でも書いてみたり、あとはひたすら論文をチェックしています。
近年アニメーションを取り扱う論文がものすごく増えました。SIGGRAPH, SIGGRAPH ASIAだけでなく、ECCV, ICCV, CVPRといったCV分野の論文、それにarXivなんかも含めると相当早いペースで論文が出ているので、それをひたすらキャッチアップすることは非常に大変ですが、ここは歯を食いしばって頑張っていく時期かな、と思っています。
会社も米中の問題等で製品を出すことが難しい中で、製品に結び付けなくても論文を出すことで外からも見れる結果を出していければと思っています。
MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentanglement, arXiv'21
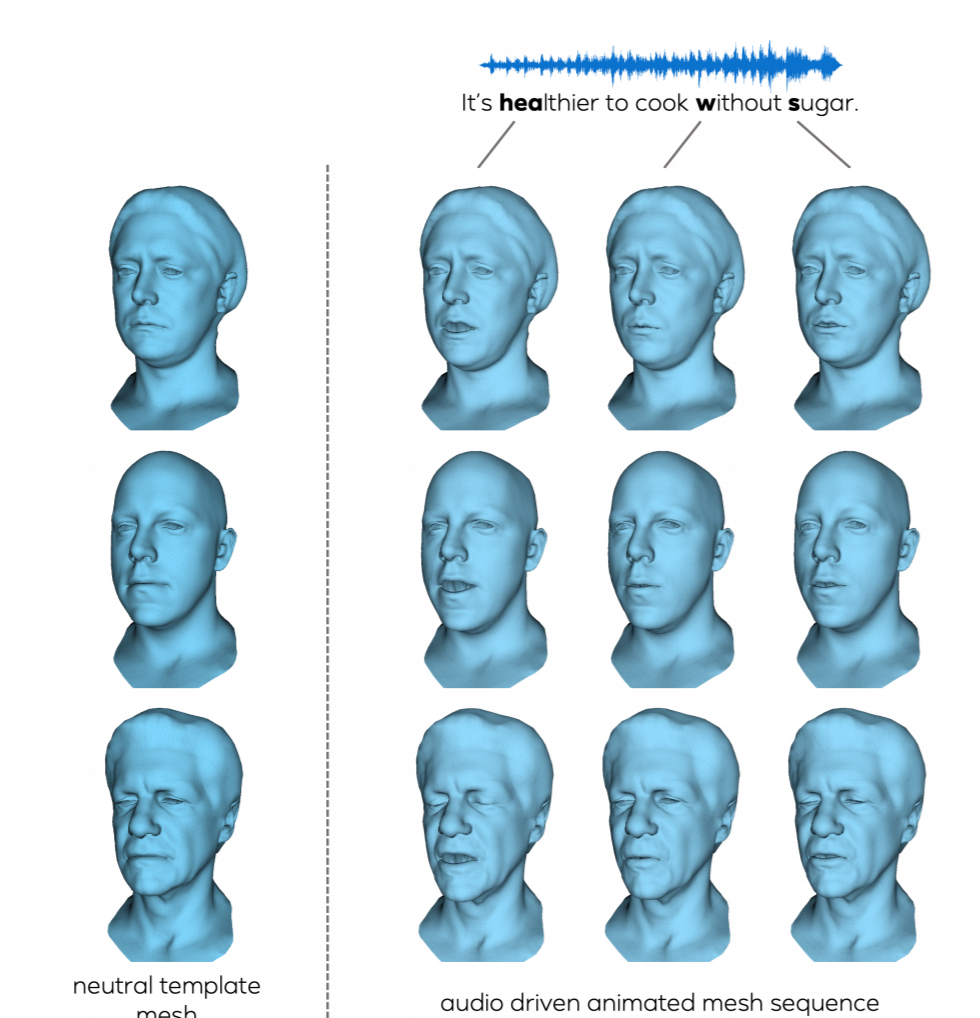
さて、本日はリップシンクのお話です。リップシンクは前から広く行われていますが、最近だとやはりMorphable Modelを使用したリップシンクアプローチが広く使われていますね。例えば、Max PlankのVOCAをはじめ、個人の顔のモデリング技術を生かしてスピーチアニメーションに繋げていく流れが盛んになりつつあります。
本論文もその流れを汲んではいるのですが、Facebookが普段研究しているCodec Avatarの技術をいよいよアニメーション生成に繋げていきたい、といった勢いを感じますね。
アニメーション分野は最近Disentangleというテーマが流行しています。シンプルな入力から、個人の顔や表情、感情、個性等の情報を分解していって、それぞれを別々に制御できるようにしたいというのが主な目的になってきています。そうすると、表情をキープしながら別のアバターを動かしたり、個性をキープしたまま、感情を変えたり、なんてことができるようになってきます。その流れが今考えられるアニメーションの究極みたいなところになってきますかね。そういった個性だったり、表情、感情といった情報に分解するために、大量の学習用データを集める必要があるので、必然的にそういった装置や技術を持っている会社、研究所が強い分野ではあります。
概要
- Audio drivenなLip sync Animation生成技術。
- Audioに相関する顔の部位、相関しない顔の部位を、Disentangleによって明らかにする。
- 主には目元のあたりは表情生成に影響し、Audioのlip sync要素は口元に影響を受けるという事をより明らかにした。
- その結果、口元をキープしたまま表情を変えたり、他のアバターに口元をretargetしたりできる。
手法
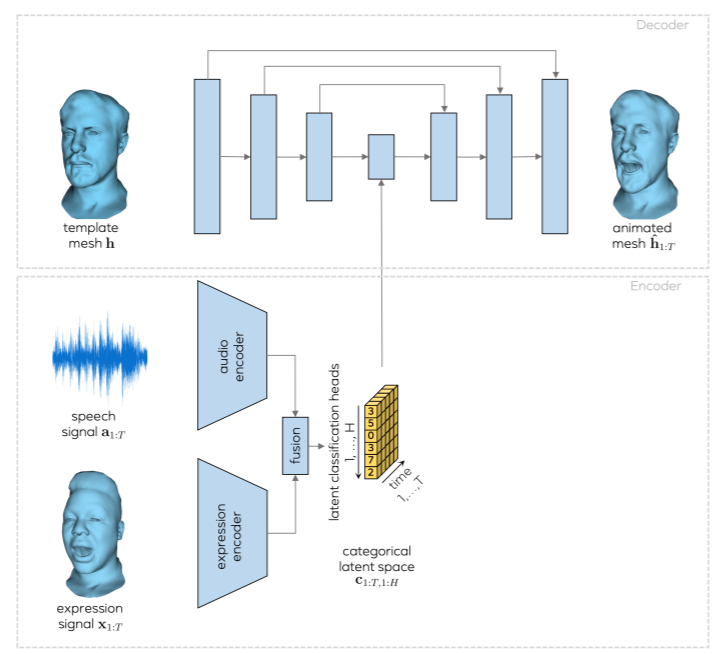
- Audio encoderとExpression encoderの出力をFusionし、二つの要素を考慮したlatent classicication spaceとする。
- Decoderでは、基本的には入力したメッシュの形状になるようなものを出力するが、この時に形状のL2ノルムをとるのではなく、 Cross-modality lossによって部位ごとのLossをとることを考える。
- Cross modality lossによって、どのAudio要素がどの部位に影響を与えるか、Expressionがどの部位に影響を与えるかを可視化することができる。
Limitation
- 低スペックのPCでは実時間での再現ができない。
- Audioの入力は100ms以上である必要がある。(映像よりだいぶ早い)
- データを集めるときにトポロジーをキープしたメッシュを用意する必要がある。(髪の毛部分や目元などのキャプチャが難しかったりする。)
まとめ
Nice Disentangleでした。