論文紹介: DreamFace: Progressive Generation of Animatable 3D Faces under Text Guidance
久々の投稿の投稿になりましたが、ここ半年はCLIPやStable Diffusion、ControlNet、ChatGPTなど話題が目白押しで、ここまで論文技術がTwitterやニュースで話題になるとは想像もしていませんでした。中でもChatGPTの登場は強烈で、人とコンピュータの対話インタフェースが機械語命令や単語検索ではなく、日常会話に置き換わった点は大きな変化です。またStable Diffusionも入力したキーワードに沿った画像を生成するというのは非常に新しい体験です。
そんな今話題の「生成AI」ですが、なんと今夏に発売予定のCV最前線「生成AI」に私が寄稿した記事が掲載されます。私の担当はジェスチャー生成で、言語や表情、動作といったマルチモーダルデータによる生成系に関する研究を紹介しています。これからより注目度が高まるテーマだと思うので是非読んでいただけたら嬉しいです。
DreamFace: Progressive Generation of Animatable 3D Faces under Text Guidance
 [ Project Page ]
[ Paper ]
[ YouTube ]
[ ChatAvatar (Service) ]
[ Project Page ]
[ Paper ]
[ YouTube ]
[ ChatAvatar (Service) ]
さて、今回紹介するのはテキスト情報からアバターを生成するという論文で、著者は最近気になるDeemos Technology。こちらの企業は大学発スタートアップで、数年前からSIGGRAPHで論文を見かけるようになりました。第一印象としては「かなりお金をかけている」という印象で、自作のLightStageを開発したりMRIを使って頭蓋骨データを収集したりしながらそれを論文やサービスとして着実に結び付けている企業です。Twitterはこちら。Deemos Tech (@DeemosTech) / Twitter ※以下はCGWORLDの記事を意識した言葉づかいで書いてみました。
概要

本論文はテキストから三次元アバター顔モデルを生成する手法を提案している。近年テキストに沿った三次元モデル生成手法に関する研究が盛んに提案されているが、いずれも陰関数表現による三次元表現やテクスチャではなく頂点カラーが用いられる等、低品質かつ互換性の低い三次元表現手法が多かった。そこで著者らは、既存プラットフォームと相性の良いトポロジーが一様な高品質なメッシュとUVが統一された物理ベースのマテリアルの二つをテキストから生成する手法を提案している。
提案手法のパートは大きくジオメトリ、テクスチャ、アニメーションの三つに分かれており、ジオメトリとテクスチャパートは、近年話題のCLIPやDiffusion Modelを微分可能レンダラーと組み合わせながらテキストと三次元アバター表現をどう橋渡しするかについて述べられている。またアニメーションパートでは、様々な人物の表情から学習された共通表情モデルを用いて、任意の人物顔の動画像入力に応じた顔形状生成手法が提案されている。
1. テキストからのジオメトリ生成(ジオメトリ)

疎な形状の生成
まずジオメトリパートでは、テキストからトポロジーが一様な疎形状(三次元メッシュ)と詳細形状(Normal/Displacement Mapにより表現)を生成する手法について提案されている。テキストから様々な顔形状を作成するにあたって、様々なパラメータに応じて顔形状が変化するMorphable Modelと呼ばれるモデルがよく使用される。本論文では、ICT-FaceKitと呼ばれる、南カリフォルニア大学の研究者らが提案した三次元顔表情モデルが使用されている。本モデルは200人以上のスキャンデータから主成分分析(PCA)によって生成された100次元のパラメータを持っており、著者らは正規分布によって様々な顔形状を生成し、レンダリングを行う。ここで、著者らは一つの顔形状に対し、正面や斜めに配置された3つカメラと10個の異なるライトコンディションにより顔画像を30枚程度レンダリングしている。その後、CLIPと呼ばれる自然言語から画像分類が可能なモデルを用いて、上記のレンダリング画像とテキストプロンプトの類似度を計算していく。この時、"the face"と入力されたときのジオメトリは平均顔形状が対応するようアンカーポイントを設定し、そこからの様々なテキストと形状が類似度によって紐づいていく仕組みとなっている。そして入力テキストに対して最も高いスコアの形状パラメータがその出力となる。ここまでが上記はテキストプロンプトから疎な形状を得るまでの道のりとなる。
詳細形状の生成
本手法の面白いところはここからである。著者らは、よりプロンプトに近い詳細な形状を得るために、ここから形状パラメータの更新に加え、Normal/Displacement Mapを生成することを提案している。先ほどはMorphable ModelとCLIPを用いて、テキストにマッチした顔のパラメータを選ぶ手法であったが、今回はNormal MapやDisplacement Mapといった高品質なテクスチャを生成する必要がある。ここで用いるのが今話題のDiffusion Model(DM)だ。なお、初期に提案されたDMでは計算負荷が高いため、より次元数の低い潜在空間で学習が可能なLatent Diffusion Model(LDM)を用いて上記データを生成している。まずテキストから生成された上記データ形式を統合したアバターを微分可能レンダラーでレンダリングし、これもテキストと同様にLDMによってエンコードしていく。その後、LDMによってエンコードされたテキストとレンダリング画像の潜在変数の誤差をScore Distillation Sampling(SDS)という手法で計算する。SDSはテキストから3Dモデルを生成する先行研究であるDreamFusionでも使用されている手法であり、テキストと三次元情報を橋渡しするベースラインとなり得るだろう。最後に微分可能レンダラーの大きな特徴でもある「逆誤差伝搬法」を通じて、LDMから出力される各潜在変数の差が小さくなるよう形状パラメータ、Normal Map、Displacement Mapを更新することで、より入力テキストプロンプトに近い詳細な出力データを得ることが可能となる。なお評価関数に関する補足として、論文内ではSDS以外にも学習前後での顔形状パラメータや形状とテクスチャそれぞれの滑らかさの差も考慮されているようだ。
2. テキストからのマテリアル生成(マテリアル)

続くテクスチャパートでは、テキストからUV空間が一様で高品質な物理ベースマテリアル画像(Diffuse、Specular、Normal)を生成する手法について提案されている。テクスチャは3Dモデルの見えに関して非常に多くの割合を締める要素であり、特に高品質が求められる人物顔表現にはDiffuse、Specular、Normalといった物理ベースのマテリアルが求められる。しかしこういったマテリアルはLight Stageのような高度な撮影機材を必要とし、現段階で公開されているデータセットには限りがある。またデータセット間で異なるジオメトリやUV空間を持っているため、常に一様なUVのマテリアルを生成することは容易ではない。そこで著者らは二つの異なるLDMを駆使してテキストプロンプトから一様なUVマテリアルテクスチャの生成を実現している。
テクスチャ空間でのDiffusion Modelの学習に関して
Diffusion Model(DM)はデノイジング(ノイズを減らしていく処理)を繰り返し行いながら画像生成を行う手法であり、非常に複雑な分布で構成されている何万枚ものテキストと画像のペアを容易に学習することができることで注目されている技術である。著者らはその事前学習済みのテキスト-画像モデルにテクスチャ生成機能を構築することを試みる。なお、ここでもジオメトリ生成の時と同様にLatent Diffusion Model(LDM)を用いることで全てのdiffusionプロセスを潜在空間上で進めることができる。しかしながらLDMは一般画像を生成するのに特化しており、一様のUV空間に顔のテクスチャを生成するようには学習されていない点が大きな課題となる。そこで著者らは自ら作成したデータセットを用いて既存モデルをfine-tuningすることでそれらを実現した。ここで用いられるフェイシャルデータセットは複数に跨ぐことから、アーティストがリトポロジやテクスチャ転写を行い、一様なUVテクスチャを収集している。またアノテーターを雇用し、各テクスチャに対して適切なプロンプトを正解値として与えている。アクターの数はなんと約560個近くにも及ぶ。しかし、これでもDiffusion Modelが学習された元データと比べると本当にわずかなデータともいえるかもしれない。データセットの中には頭にヘアキャップが映り込んでいる場合があるため、こういった画像は肌領域検出モデルにより、顔ではない部分をマスクとして生成する事で安定した顔領域の学習を可能にしているそうだ。
なお、顔データセットにはDiffuse画像でもSpecularが映り込んでしまっているテクスチャが存在し、これらに基づいて学習、生成すると最終的に欲しい純粋な画像を得ることはできない。そこで、欲しい画像と欲しくない画像それぞれの領域を特定し、生成時に欲しい画像のみを生成するプロンプトを指定できるtexture LDMなるものを提案した。なお、手作業で該当するプロンプトを追加していく作業(いわゆるプロンプトエンジニアリング)は非常に手間がかかる上に不安定でもあるため、幅広いテキストプロンプトを欲しい画像が得られるようなプロンプトを自動で選択してくれる手法(Prompt Tuning)を行い、任意のテキストから欲しい画像のみを生成することを可能にした。
効率的な生成モデルの実現
ここからがマテリアル生成のメインの話となる。著者らはテクスチャの品質を保持しながら効率的に学習を進めるために、SDSを用いて二つのLDM(Generic LDMとTexture LDM)をそれぞれ2つのステージ(潜在空間と画像空間)で使用するTwo-stage dual pathという手法を提案している。
まずStage 1となるLatent Space SDSでは、入力したプロンプトに合うレンダリング画像とテクスチャ画像を生成するGeneric/Texture LDMをそれぞれ学習していく。ここでは、SDSを用いて入力されたプロンプトとそれぞれの出力画像との間のSDSによるLossが小さくなるようなそれぞれレンダリング/テクスチャを出力するLDMを学習していく。
続いてStage 2では、入力されたプロンプトからTexture LDMを通して得たテクスチャをデコードして生成されたDiffuse Mapを顔モデルに貼りつけて、異なるビューとライト環境によってレンダリングする。そのレンダリング結果をエンコードした潜在変数がプロンプトからGeneric LDMを通じて生成された潜在変数がSDS Lossで小さくなるように、Generic/Texture LDMを学習していく。異なるライト環境によってレンダリングすることでDiffuseからスペキュラー成分をなるべく排除したDiffuseマテリアル生成が実現できるようになる。


高解像度なテクスチャ生成
最終的に、Texture LDMによって生成された画像に対して、image-to-image translationとTexute Augumentationによって高解像なDiffuse、Normal、Specular画像を出力する。なお、データセットによって解像度等が異なるため、まずは64x64から512x512への変換ではRestoreFormerと呼ばれる顔画像復元手法を適用し、さらに4K画像を得るためには、Real-ESRGANと呼ばれるsuper-resolutionモデルを使用している。最後の4K画像生成には彼らの独自データセットが訓練データとして与えられているようだ。

3. 動画像からの表情復元(アニメーション)

最後のアニメーションパートでは、様々な人物の表情から学習された共通表情モデルを用いて、任意の人物顔の動画像入力に応じた顔形状生成手法について提案されている。既存のパイプラインではブレンドシェイプを用いて顔のアニメーションを行う場合が多いが、本手法ではより個性化されたアニメーションを生成するために、Expression encoderによって動画像から変換された表情の潜在変数をGeometry Generatorへの入力とすることで、任意のNeutral形状に対する個性化された表情を生成することを可能にしている。ちなみに、本手法では、Expressionの潜在変数から都度ジオメトリが生成される手法であるため、Blendshapeと比較すると実時間性に劣るといった欠点もありそうだ。しかしながら、線形な表情のみを生成するブレンドシェイプモデルに対して、本手法では非線形的な顔動作を生成できることが期待できるため、高い表情表現を実現できそうである。
統一的表情モデルを実現するネットワーク(Cross-Identity Network)
この時、Expression EncoderにIdedntity要素が入らない、つまり画像からすべての人物に共通の表情に関する潜在変数を得るために、Cross-identity hypernetworkというものが提案されている。この手法はCaoらがSIGGRAPH 2022にて発表したUniversal Prior Modelから着想を得ており、入力となる表情のジオメトリと、出力となる同一人物の無表情とExpression encoderの出力から生成された表情のジオメトリの二つの誤差が小さくなるようにU-Net構造のExpression Networkが学習するような設計となっている。
ビデオ入力によるアニメーション生成
本手法は、ニューラルネットワークを用いた表情モデルでもあることから、手作業で直感的に編集することが難しいモデルでもある。そのため、ジオメトリやテクスチャをテキストから生成したように、異なるモーダル、本手法では顔の動画像からそれに応じた表情を生成する手法を提案している。その手法もCross Identity Networkと同様に、生成されたジオメトリとテクスチャからレンダリングされた画像をExpression Networkの入力とし、その潜在変数と無表情の形状をGeometry Generatorへの入力とすることで、互いの誤差を最小化するように学習を行っている。なお、本論文全体を通した顔のジオメトリ表現は、三次元頂点座標をUV空間に落とし込んだPosition Mapを用いている。

結果と今後の展望
いずれの手法もAblation Studyや他手法との比較を行い、優位性が高いことを示している。今後は目や歯といった顔のパーツの生成や動的なテクスチャ生成、そしてテキストプロンプトによるアニメーションの生成など、様々な課題に取り組んでいくことと思われる。


編集後記
今回はかなり詳細まで読み切ってまとめてみた。冒頭で紹介したような雑誌への寄稿や日常的に論文情報を得られる情勢もあり、手軽だけどディープに技術を追えるメディアがあってもいいように感じている。今回は意のままに書いてしまったため長文となったが、今後は情報の取捨選択を行いながら、すっきりと読みやすい記事にしていきたい。また雑誌のようなレイアウトだともう少しキャッチーに読めるのかなと思案中。。。
論文紹介: Skeleton-free Pose Transfer for Stylized 3D Characters
こんにちは、iwanao731です。もう一年以上も本ブログを書いておらず2022年ももうすぐで終わりに近づいています。最近は本当に技術進歩が速く、仕事でも最新情報にキャッチアップするのに一苦労しています。そんな中でもなんとかモーション生成系で論文が通ったりしています[1][2]が、スキニングや表情アニメーション系で論文を通すまでに至るにはまだまだ修行が必要そうです。
Skeleton-free Pose Transfer for Stylized 3D Characters, ECCV 2022
 [ Project Page ] [ Paper ] [ Code ]
[ Project Page ] [ Paper ] [ Code ]
今回の記事では変形リターゲットに着目した論文を紹介しようと思います。本論文は論文発表で参加していたECCV2022のポスターでたまたま見かけた論文で、非常に面白い技術だなと思ったので一人で著者に質問攻めしていました。Adobeも、Mixamoをはじめカートゥーン系の3Dキャラクタ技術を開発していますね。この辺りの技術はずっと興味があるのでこれからもずっと追っていきたいテーマでもあります。
概要
キャラクタアニメーションの分野では、あるキャラクタの動きを別のキャラクタにリターゲットしたい機会が非常に多くあります。しかし、キャラクタごとに体型や骨の数、トポロジーが異なっていたりして満足にアニメーションするには対応するジョイントのペアや対応点の作成等、様々な事前処理が必要でした。ジョイントを使用したリターゲット手法の場合、リギングやスキニングといったセットアップ済みのキャラクタを用意する必要があります。本手法はそういったジョイント情報を用いず、ソースとターゲットのメッシュから変形後のメッシュを出力するネットワークを提案しているため、そういった事前処理を必要としない点が非常に新しいと思いました。
モーションのリターゲットについて紹介した記事はこちら iwanao731.hatenablog.com
メッシュからメッシュへの変形はDeformation Transferという手法がリターゲット目的で広く使用されていますが、トポロジーや体型が大きく異なっていたり、複数オブジェクトで構成されているキャラクタに対して適用するのは困難です。本手法では、内部的にリギングに近いような処理も入っており、そのあたりは以前紹介したNBSを参照しているようです。しかし、NBSとは異なり、よりキャラクターっぽいモデルに適用できるように関節の階層構造をなくしたり、より多様なモデルでもうまくいくようなデータセットを構築し学習を行っています。(NBSはSMPLみたいなボディしか適用していないので、服を着ていたり、キャラクタっぽいモデルではうまくいかないですよね)
手法
リターゲットの考え方としては、フェイシャルのリターゲットにもアイデアとして通じる部分があると思います。フェイシャルの場合、ソースとターゲットのIdentityとExpressionを分離して学習することで同一のExpressionを異なるIdentityで表現するといったリターゲットをよく行います。 iwanao731.hatenablog.com
本手法も同様に、ニュートラルポーズとポーズ後をそれぞれ別々のネットワークに入力していきます。
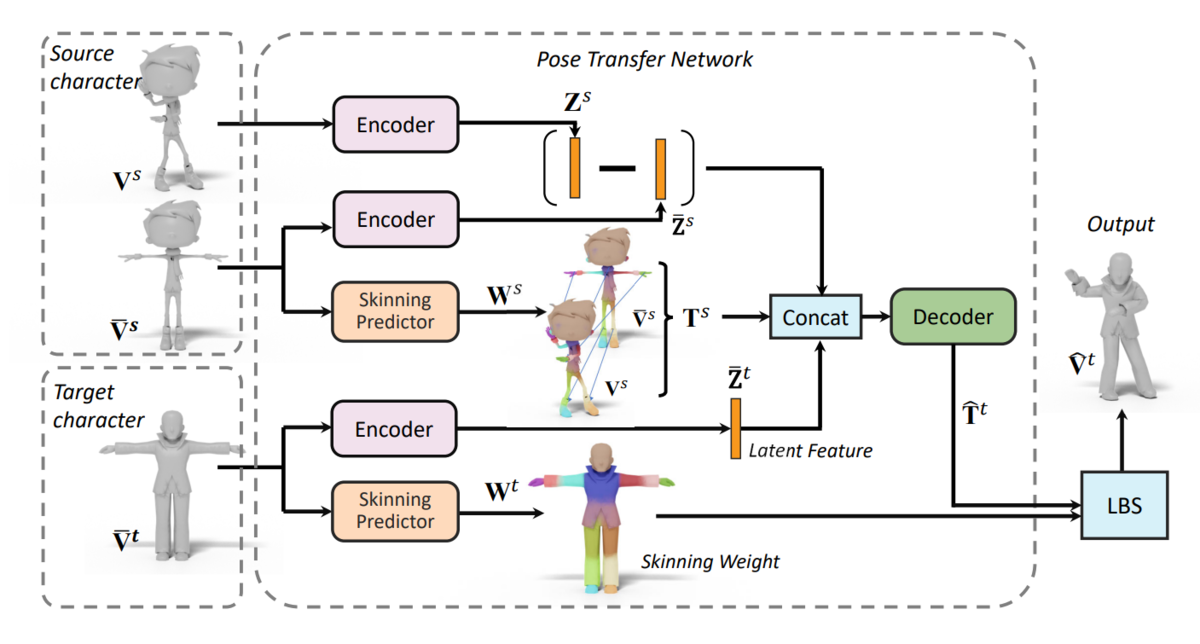
- ソースのニュートラルポーズとポーズ後に対してそれぞれGraph Convolution NetworkベースのEncoderを適用し、二つの特徴量が近い値になるようにする(Identityをキープしようとするネットワーク)
- ソースのニュートラルポーズとポーズ後間でトポロジーが同一のため、スキニングウェイトを推定するネットワークを通じて二つのメッシュ間の変形ジョイントの行列T_hatを計算可能。
- ターゲットのニュートラルポーズからEncoderを通じて特徴量を計算し、ソースの情報を集約することでリターゲットの変形ジョイントTを推定。
- ターゲットのニュートラルポーズからスキニングウェイトを推定し、T_hatを適用し、ポーズ後の形状を計算。
ジョイントの数はキャラクタによって異なりますが、本ネットワークでは40個として計算しているそうです。実際にスキニングウェイトはこのジョイント数に基づいて計算されますが、不要なジョイントはウェイト0として計算されるそうなので、キャラクタごとに適切なジョイントの数がウェイトから計算される点が非常に面白いと思いました。
使用するデータセット
上記学習を行うためにはポーズ前とポーズ後のペアデータセットが必要となります。彼らの研究では、AMASSデータセットとMixamoで作成したデータセットを用いているようです。特にAMASSデータはSMPLがベースになっているため、ポーズのパラメータを変えながらポーズは同一にすることでデータを多く作成しているようです。また、Mixamoのデータセットでは公開されている100以上のキャラクタと2000種類以上のモーションから異なるキャラクタ間で同じポーズをしているデータセットを作成しているそうです。
さらに面白いのは上記のデータセットだけでなく、RigNetのデータセットも用いている点。
こちらの記事でRigNetが少しだけ紹介されています。 iwanao731.hatenablog.com
RigNetは様々な形状のキャラクタに対してRiggingが施されていますが、共通のポーズデータは存在しません。そこで用いているのがCycle Consistency Loss。こちらは、Vs, V'sの変形を一旦Vtに適用して作成したV't'を、今度はVt, V't', Vsを用いてV's'を計算し直し、V'sとV's'の誤差を最小化しようとするもの。説明すると少しわかりづらいですが、ターゲットで予想された変形からソースの変形を生成し、正解と一致するかどうかを計算しています。近年のスキニング変形系の論文ではこのLossが広く用いられている気がします。ただし、これだけだと、圧倒的にニュートラルポーズのデータが多く、ポーズ後のデータが少ないため、安定しない問題があるようなので、上記のLossに加えて、ソースの変形を無理やりターゲットに適用して疑似的に作ったターゲットとCycle Consistency Lossで計算したターゲットの形状の誤差もとっているそうです。(細かい表記はうまく表示できていないかもしれないので当てにしないでください><)

本ブログではこれ以上は詳しくは書きませんが、上記に加えて下記を元に最適化を行っているようです。下記著者ポスターより引用
- 頂点間の距離の誤差
- 変形行列間の誤差
- スキンウェイトの誤差
- エッジ距離の誤差

結果
彼らの論文では、NBSとPinnocchio、Skeleton-aware Network (SAN) 、 Shape Pose Disentangle (SPD)の手法と比較を行っています。

比較手法としては、Point-wise Mesh Euclidean Distance(PMD)というMetricを採用しているそうです。詳しくは調べていないですが、正解メッシュと推定メッシュの対応頂点間のユークリッド距離の総和を誤差にしていると思われます。
結果をみるとPinnochioが意外とうまくいっているというのと、提案手法はきれいにできているなという印象です。ちなみにリターゲットで計算されている行列Tは階層構造がない単独のJointであるため、従来のアニメーションシステムの中で手動でポーズを変えた結果を反映したい場合に、前のジョイントの変形を引き継ぐ、といったことはできないと予想されます。その場合はソースモデルを変形することで対応できそうです。
比較論文の一部はこちらでも簡単に紹介しています。 iwanao731.hatenablog.com
まとめ
ポーズ前とポーズ後のメッシュからポーズ後のターゲットメッシュを作成できる研究を今回紹介しました。リターゲットを考える際に結果的にリギングをしている(スキニングウェイトやジョイントを計算している)のが面白いですね。ただし、本手法はターゲットのニュートラルポーズ(Tポーズ)が必要というのがLimitationだそうです。アーティストが作成した3Dモデルはだいたいニュートラルポーズで作られていますが、ぬいぐるみやフィギュア、マネキンなどはだいたいポーズが付けられてしまっているので、それをスキャンして別のポーズにしたいといった場合には適用するのが難しそうです。こういったケースに対応するために、今後はポーズ後をポーズ前(ニュートラルポーズ)に変形する手法[ 関連研究 ]があるとよさそうですね!
論文紹介: Learning Skeletal Articulations with Neural Blend Shapes
お久しぶりです、iwanao731です。 三か月ぶりの投稿です。最近仕事でDeep Learning始めました。2017年に卒業してからはしばらくはそれまでのアニメーション知識で何とかなっていたんですが、アニメーション分野もDLの流れに飲まれそうになってきたのでPytorchのチュートリアルやりながら論文の追実装等をしています。
色々と使いこなせるようになったらプライベートでも論文を書いて課外活動をしたいなと思っています。
Learning Skeletal Articulations with Neural Blend Shapes
youtu.be [ Project Page ] [ Paper ] [ GitHub ]
さて、今日は久々にリギングやスキニングのお話。 ここ1,2年でキャラクタやアタバーのスキニングに関する論文が増えてきています。その中で引用数を増やしているのが以前紹介したSMPLという論文。
概要
この論文では、人の体型をパラメトリックにしたものなのですが、実は体型だけでなく、姿勢に依存した変形も考慮したブレンドシェイプを再現しているんですね。 この体型モデルによって、動画から体型を推定しながらアニメーションさせて、自然なスキニングも再現できるのですが、一方で任意のキャラクタや4Dデータを入力として任意のアバターを作るようなケースでは、リトポロジーを行わなければならないといった大きな課題がありました。
本論文では、そういったリトポロジーを必要とせず、なおかつリギングも同時に行いながら、モーキャプのモーションを適用可能なセットアップを自動でやってくれる、といった至れり尽くせりな論文となっております。
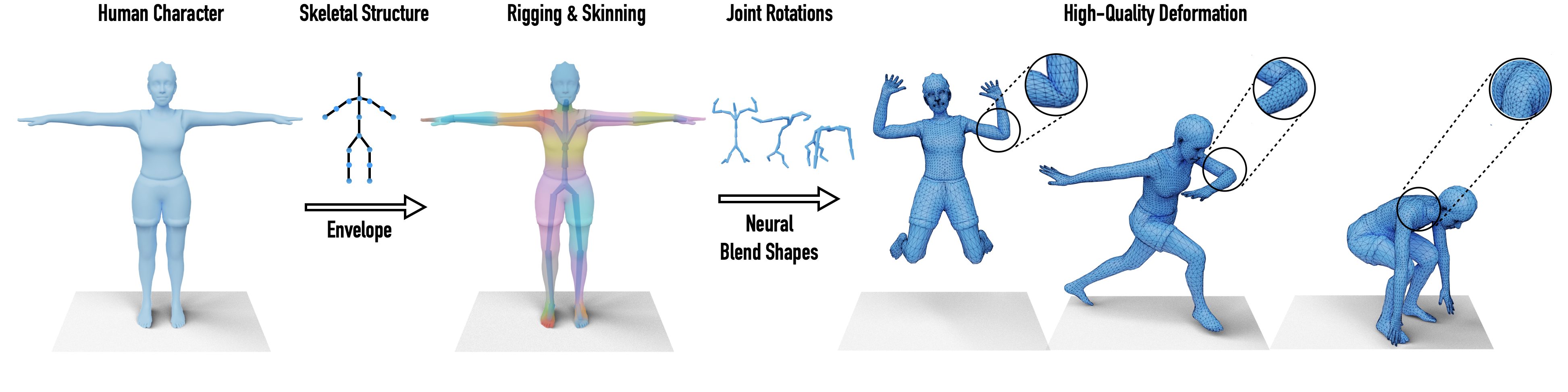
手法
本手法が素晴らしいのはメッシュのトポロジーへの依存が少ないという点です。つまり、様々な頂点数のキャラクタ/アバターのメッシュに対して、リギング、スキニングを行うことができます。それを実現するためにMeshCNNと呼ばれる技術を使っています。MeshCNNは、Deep Learningの分野で画像に対して行われるCNNの処理に近いConvolutionをMeshに対してできる技術で、SIGGRAPH'19に発表されたものです。
トレーニング時にテンプレートとなるメッシュをMeshCNNでConvolutionし、Deep Vertexと呼ばれる洗剤空間とSkinning Weightをそれぞれ出力するようにし、最終的にそれらからDecodeしたモデルが、テンプレートをあるポーズにスキニングした結果になるようにするようにします。(Envelope Branch)
最終的には、任意のメッシュのテンプレートとスケルトンを入力するとジョイントの位置とスキニングウェイト、そしてポーズに依存した変形要素を生成し、ポーズ情報からそのブレンドウェイトを自動推定するといった流れになっています。
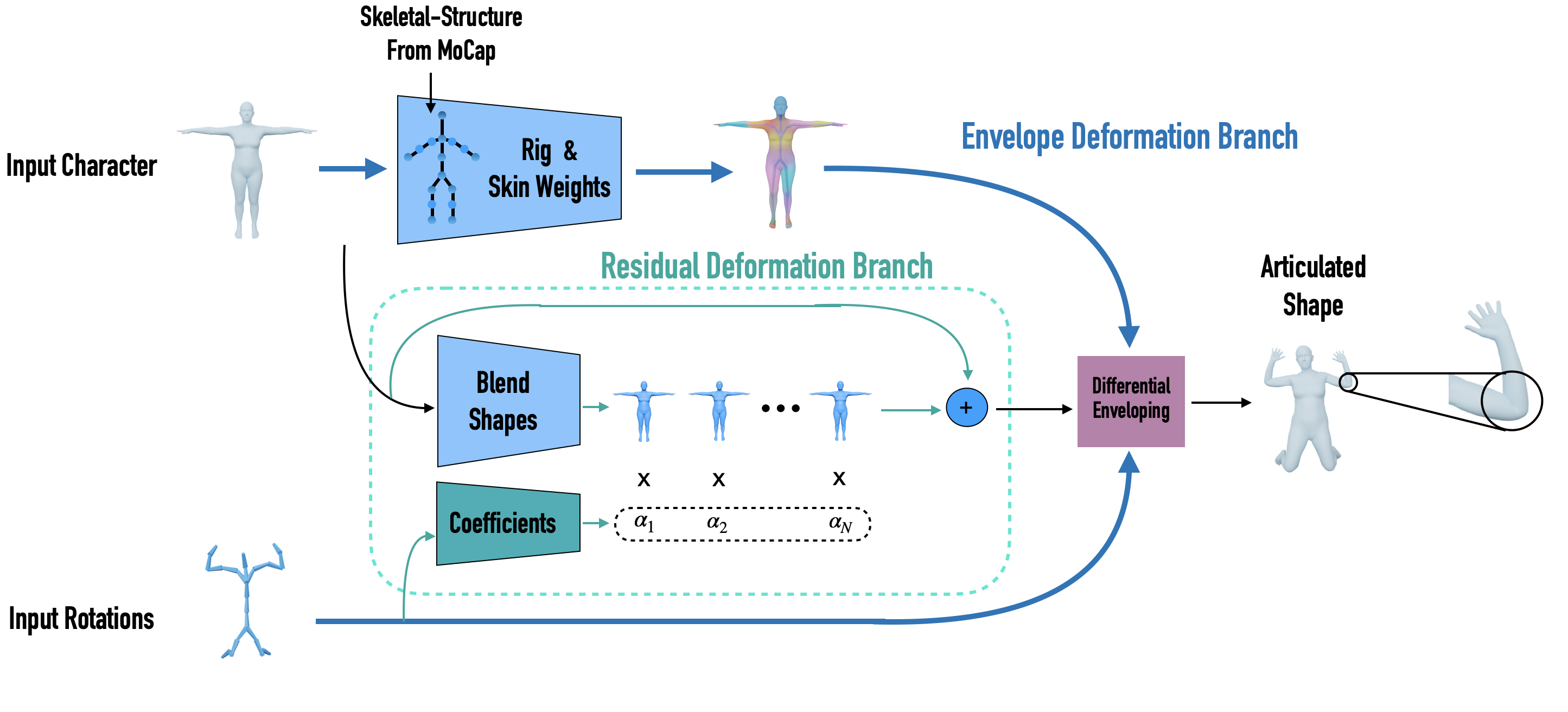
画期的な点
既存のリギング手法では、任意の任意のスケルトン構造で推定することができず、モーションリターゲットしづらいといった問題があったのですが、本手法ではモーションリターゲットをサポートできるように任意のスケルトン構造でリギングとスキニングを同時に行うことができる点がまず素晴らしいと思います。
また、ポーズに依存した変形をブレンドシェイプとしてassignし、ポーズ情報からそのブレンドウェイトを推定するというのも、現在のゲームエンジンプラットフォームに非常に溶け込みやすい技術として設計されています。
まとめ
自分もこれやりたかったので先にやられてしまいましたが、とにかく素晴らしい論文だなと思いました。 コードも公開されており試してみましたが、スキニングやリギングの精度はまだまだ改善点はありそうです。
論文紹介: MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentanglement
こんにちは、iwanao731です。
コロナ禍二年目ですが、相変わらず変わらない生活が続いていますね。第一回の緊急事態宣言に比べて飲食店での酒類の提供ができなくなってしまったので、遠くにも行ってはいけないし、外で飲むこともできない、といった難しい生活。そんな中で趣味の川崎フロンターレのサッカー観戦(DAZN)や近所のワインショップで買った自然派ワインで何とか楽しく過ごせています。
会社の仕事は今まで敬遠していたDeep Learningに取り組み始め、CG研究を始めてから10年という節目でもあるため、自分の中で第二章が始まろうとしているといった感じです。やるテーマがアニメーションやリギングに関することであることには変わりないですが、自分の中で表現できるスキルを広げていければ、自分のアイデアをカタチにすることがより多くできてくると思っています。なかなかDeep Learningの研究には慣れないですが、サンプルプログラムを参考にしつつ、自分でも書いてみたり、あとはひたすら論文をチェックしています。
近年アニメーションを取り扱う論文がものすごく増えました。SIGGRAPH, SIGGRAPH ASIAだけでなく、ECCV, ICCV, CVPRといったCV分野の論文、それにarXivなんかも含めると相当早いペースで論文が出ているので、それをひたすらキャッチアップすることは非常に大変ですが、ここは歯を食いしばって頑張っていく時期かな、と思っています。
会社も米中の問題等で製品を出すことが難しい中で、製品に結び付けなくても論文を出すことで外からも見れる結果を出していければと思っています。
MeshTalk: 3D Face Animation from Speech using Cross-Modality Disentanglement, arXiv'21
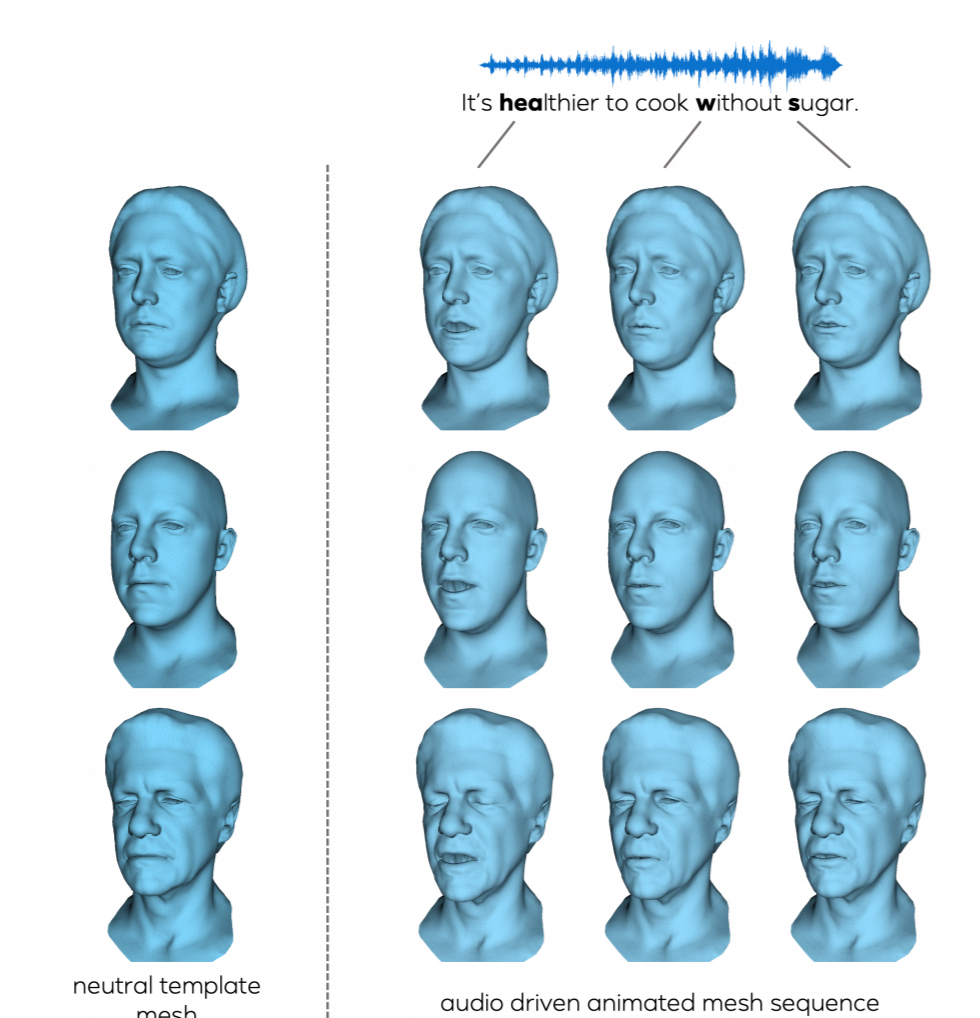
さて、本日はリップシンクのお話です。リップシンクは前から広く行われていますが、最近だとやはりMorphable Modelを使用したリップシンクアプローチが広く使われていますね。例えば、Max PlankのVOCAをはじめ、個人の顔のモデリング技術を生かしてスピーチアニメーションに繋げていく流れが盛んになりつつあります。
本論文もその流れを汲んではいるのですが、Facebookが普段研究しているCodec Avatarの技術をいよいよアニメーション生成に繋げていきたい、といった勢いを感じますね。
アニメーション分野は最近Disentangleというテーマが流行しています。シンプルな入力から、個人の顔や表情、感情、個性等の情報を分解していって、それぞれを別々に制御できるようにしたいというのが主な目的になってきています。そうすると、表情をキープしながら別のアバターを動かしたり、個性をキープしたまま、感情を変えたり、なんてことができるようになってきます。その流れが今考えられるアニメーションの究極みたいなところになってきますかね。そういった個性だったり、表情、感情といった情報に分解するために、大量の学習用データを集める必要があるので、必然的にそういった装置や技術を持っている会社、研究所が強い分野ではあります。
概要
- Audio drivenなLip sync Animation生成技術。
- Audioに相関する顔の部位、相関しない顔の部位を、Disentangleによって明らかにする。
- 主には目元のあたりは表情生成に影響し、Audioのlip sync要素は口元に影響を受けるという事をより明らかにした。
- その結果、口元をキープしたまま表情を変えたり、他のアバターに口元をretargetしたりできる。
手法
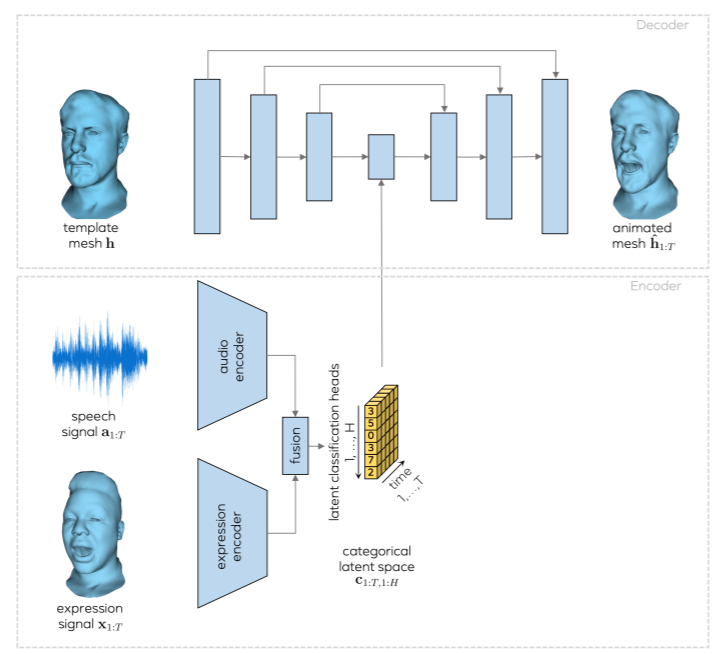
- Audio encoderとExpression encoderの出力をFusionし、二つの要素を考慮したlatent classicication spaceとする。
- Decoderでは、基本的には入力したメッシュの形状になるようなものを出力するが、この時に形状のL2ノルムをとるのではなく、 Cross-modality lossによって部位ごとのLossをとることを考える。
- Cross modality lossによって、どのAudio要素がどの部位に影響を与えるか、Expressionがどの部位に影響を与えるかを可視化することができる。
Limitation
- 低スペックのPCでは実時間での再現ができない。
- Audioの入力は100ms以上である必要がある。(映像よりだいぶ早い)
- データを集めるときにトポロジーをキープしたメッシュを用意する必要がある。(髪の毛部分や目元などのキャプチャが難しかったりする。)
まとめ
Nice Disentangleでした。
論文紹介: MotioNet: 3D Human Motion Reconstruction from Monocular Video with Skeleton Consistency
お久しぶりです,iwanao731です.2021年初投稿ですね.あけましておめでとうございます. 相変わらず2021年もコロナの状況は変わっておらず,緊急事態宣言も続いている最中ですが,コロナに振り回されず,今やれることをやっていかないとですね. とりあえず最近は色々と作っていて,昨年興味があって色々と読んでいたVolumetric Videoに関しては,4DVIEWSで撮影したデータを使って,ポーズに依存した変形ができるアバターなんかを実験で作っておりました.
まだまだプロトタイプなのですが,色々と難しいことをやらないといけなくて,なんといってもメッシュのトラッキングですね.これが地味に難しくて,色々と工夫してました.まだ道半ばという感じですが.
さて,今日は今月末に開催されるSIGGRAPH ASIA勉強会に向けて各論文を読んで忘れないようにまとめようと思い,そのうちの一本の論文を取り上げます.
MotioNet: 3D Human Motion Reconstruction from Monocular Video with Skeleton Consistency
[ Project Page ] [ Paper ] [ Code ]
概要
- ビデオから二次元のジョイント位置を抽出し,三次元のジョイントの回転情報を取得する研究
- スケルトンはボーンの長さによって表現されており,左右対称で,単一の人物のみであることを仮定
- 動きは動的であり,スケルトンは独立.回転の角度で動作が定義されており,ルート位置がグローバルかつ足の接地情報を出すことができる.
最初に思った疑問
モーションデータをどう学習することで角度の取得を可能にしたのか
- 学習するモーションデータセットは,様々な人の異なるモーションデータで,いずれもなめらかなデータであることを仮定
- 単一の人物のスケルトンで,グローバルポジションを持っている
- 学習時は,三次元モーションを任意のビューで二次元にプロジェクトションして,ネットワークで三次元やその他の情報を復元するように学習
グローバルの位置や接地情報はどうラベル付するのか
- 足の接地についても,足の位置を事前に調べておいて,設定した床からコンタクトを判定
オリジナリティや技術的貢献はどこか
Two-branch network
単一の静的なスケルトンを出すネットワークと,ジョイントの回転,ルート位置,足の接地といった動的な動作の要素を復元するネットワーク.使用しているコンポーネントは以下の3つ.
- Forward kinematics layer by [Villegas, 2018]
Original paper is using for motion retargeting, but we use for pose estimation
Discriminator to joint rotation angle [Kanazawa, 2018]
- 絶対角度の値を使うところやフレームごとで行う点がオリジナルと異なるらしい
角速度の一定のシーケンスのリアリズムを判別するDiscrimnatorである点も異なる
1D temporal convolution [Pavllow, 2019]
- They used it for 3d pose estimation
- We used to train to lift 2d joint position into 3D with training to convert joint positions to rotation
Tips
モーションデータごとにTポーズ時の角度の絶対値が違う問題等があるため,基本的にはポーズはangle velocityに基づいたものを使っているそう.また,リファレンスとなるTポーズを学習にも使っているそう.(要調査)
その他の情報
データについて
- CMU Motion capture dataset
- Human 3.6M
11人で17シナリオのデータセットを使用
評価について
- Quantitative, Qualitativeそれぞれ異なる研究をターゲットとして比較している
- 結論として,ジョイントの位置の推定精度はトップではないが良好.角度に関してはいい結果が得られた.
感想
- ジョイントの絶対座標も取れるビデオ入力のモーションキャプチャはこれから確実に使われまそうです.
- IKを使わないので,シンプルにビデオの入力に近い動きが取れるし,実際キャプチャしたモーションの精度も高そうでそこそこ使えそう.
- 論文長い.
論文紹介: Semantic Deep Face Models
お久しぶりです.久々に論文をまとめようと思ってます. なんと11月はじめにコロナ陽性になりまして,ホテル療養や自宅隔離をしていたらあっという間に11月が終わりそうです. その間にフロンターレが優勝したり,キングダムを全巻読んだり,そして論文を読んだりして,なんだかんだで充実した11月でした. 今年ももうすぐ終わりですね.来年は顔だけじゃなくて,モーション系の知識も蓄えながら,でぃーぷらーにんぐの実装もしていこうかな,なんて思ってます.
概要
Semantic Deep Face Models
関連研究
近年,Morphable Modelを利用した顔関連論文が後をたたない一方で,Morphable Modelの欠点を指摘して,独自にデータベースを作る研究なんかも増えてきていますね.Morphable Modelの欠点は何かというと,IdentityとExpressionが完全に切り分けられていないことです.例えば,無表情で目が細い人がいたときに,IdentityとExpressionをあわせて推定してしまうと,対象人物が目を細めている表情として推定されてしまう恐れがあるということです.なので,IdentityとExpressionを分解する,Disuntangleするという研究が近年で注目されてきています.
今回の研究はDisney Researchによる研究なのですが,Disney Research研究あるあるのBeelerらのスキャニング技術を今回も使っています.しかし,従来彼らがやってきた変形系の話ではなく,顔のパラメトリックモデルを作るという研究を打ち出してきたので,流れに乗ってきたなと僕は個人的に思いました.
この手の研究は既に(といっても去年くらいからだが)Hao Liの研究チームもLight Stageで取得したデータを活用して,更に口内や眼球といったパーツの情報も分解したパラメトリックモデルを公開して,表情もFACSベースだったりするのでかなり有用なデータになっています.こちらのデータは[ ICT-FaceKit ]としてリリースされました. iwanao731.hatenablog.com
そして,近日そのHao Liのグループの最新論文についてもまとめようと思っているのですが,その論文もIdentityとExpressionをどう切り分けるかという話なのでもろかぶりですね!
提案手法
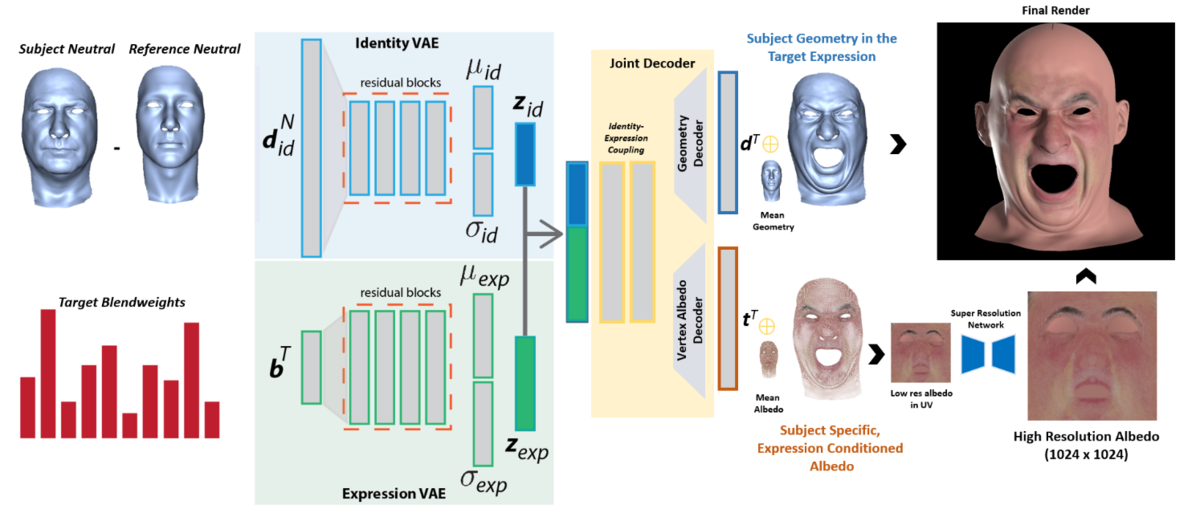
まず,データセットとして,Beelerらのスキャナーを使った224人x24種類の表情と17人分のフェイシャルワークアウト(かっこいい呼び方)データを取得します.そしてある人の表情24個(位置合わせ済み)をブレンドシェイプのターゲットとして登録し,その人のリトポ済みのワークアウトメッシュデータをターゲットとして,ブレンドシェイプの係数を推定します.そして,こちらの図の入力上部が対象者の無表情メッシュ,下部が推定されたブレンドウェイトとして,それぞれIdentity VAEとExpression VAEでlatent spaceに変換します.そして最後にJoint Decoderを使ってメッシュに戻すのですが,それとワークアウトによってキャプチャしたメッシュとのLossをとってモデル化していく,といったプロセスです.このJoint Decoderが,Identity-based expressionを作るという意味合いで今回の主な提案技術となっています.
結果
このモデルを使うと,例えば,無表情から笑顔になるといった表情変化も,線形の場合とは異なり,最初に笑った表情になってから口が開いていくといった非線形的なアニメーションを実現できるそうです.

あとは,Expression固定でIdentityを変化した場合も,人による表情の違いが再現できていると言えそうです.

ランドマークからブレンドウェイトの推定を行うことで,表情トラッキングを実現するスキームも確立されていました.
Limitation
ここはあまり理解できなかったのですが,与えられたブレンドシェイプ係数に対して,意味の持った形状を生成できる保証がない,と述べられています.これはおそらく,見た目的に形状が破綻したとしても,形状が破綻しているかどうかが計算上判別がつかない,といったことだと思います.通常であればアーティストが設計したブレンドシェイプターゲットがあって,0-1の値が入るのでたいてい表情が崩れることはないのですが,それでも組み合わせによっては大いにおかしくなるため,それと同様の問題があるといえるでしょう.
結論
画像からランドマークを検出してexpressionを推定するスキームはあったが,Identityを画像から推定するスキームが示されていなかったのが気になる.以前のHao Liの論文でもIdentityをlatent spaceでいじれるけど,そもそもそのlatent spaceのパラメータをどうやって推定するのかというところが気になるところであります.
論文紹介: [SIGGRAPH 2020] Face and Full Body Motion
Face and Full Body Motion [ Link ]
The Eyes Have It: An Integrated Eye and Face Model for Photorealistic Facial Animation
[ Project Page ]
[ Paper ]
Fast and Deep Facial Deformations
[ Project Page ]
[ Paper ]
[ Video ]
[ Sample Code ]
[ Sample Trained Model ]
Accurate Face Rig Approximation With Deep Differential Subspace Reconstruction
[ Paper ]

RigNet: Neural Rigging for Articulated Characters
[ Project Page ]
[ Paper ]
[ Code ]
[ Dataset ]