論文紹介: Skeleton-free Pose Transfer for Stylized 3D Characters
こんにちは、iwanao731です。もう一年以上も本ブログを書いておらず2022年ももうすぐで終わりに近づいています。最近は本当に技術進歩が速く、仕事でも最新情報にキャッチアップするのに一苦労しています。そんな中でもなんとかモーション生成系で論文が通ったりしています[1][2]が、スキニングや表情アニメーション系で論文を通すまでに至るにはまだまだ修行が必要そうです。
Skeleton-free Pose Transfer for Stylized 3D Characters, ECCV 2022
 [ Project Page ] [ Paper ] [ Code ]
[ Project Page ] [ Paper ] [ Code ]
今回の記事では変形リターゲットに着目した論文を紹介しようと思います。本論文は論文発表で参加していたECCV2022のポスターでたまたま見かけた論文で、非常に面白い技術だなと思ったので一人で著者に質問攻めしていました。Adobeも、Mixamoをはじめカートゥーン系の3Dキャラクタ技術を開発していますね。この辺りの技術はずっと興味があるのでこれからもずっと追っていきたいテーマでもあります。
概要
キャラクタアニメーションの分野では、あるキャラクタの動きを別のキャラクタにリターゲットしたい機会が非常に多くあります。しかし、キャラクタごとに体型や骨の数、トポロジーが異なっていたりして満足にアニメーションするには対応するジョイントのペアや対応点の作成等、様々な事前処理が必要でした。ジョイントを使用したリターゲット手法の場合、リギングやスキニングといったセットアップ済みのキャラクタを用意する必要があります。本手法はそういったジョイント情報を用いず、ソースとターゲットのメッシュから変形後のメッシュを出力するネットワークを提案しているため、そういった事前処理を必要としない点が非常に新しいと思いました。
モーションのリターゲットについて紹介した記事はこちら iwanao731.hatenablog.com
メッシュからメッシュへの変形はDeformation Transferという手法がリターゲット目的で広く使用されていますが、トポロジーや体型が大きく異なっていたり、複数オブジェクトで構成されているキャラクタに対して適用するのは困難です。本手法では、内部的にリギングに近いような処理も入っており、そのあたりは以前紹介したNBSを参照しているようです。しかし、NBSとは異なり、よりキャラクターっぽいモデルに適用できるように関節の階層構造をなくしたり、より多様なモデルでもうまくいくようなデータセットを構築し学習を行っています。(NBSはSMPLみたいなボディしか適用していないので、服を着ていたり、キャラクタっぽいモデルではうまくいかないですよね)
手法
リターゲットの考え方としては、フェイシャルのリターゲットにもアイデアとして通じる部分があると思います。フェイシャルの場合、ソースとターゲットのIdentityとExpressionを分離して学習することで同一のExpressionを異なるIdentityで表現するといったリターゲットをよく行います。 iwanao731.hatenablog.com
本手法も同様に、ニュートラルポーズとポーズ後をそれぞれ別々のネットワークに入力していきます。
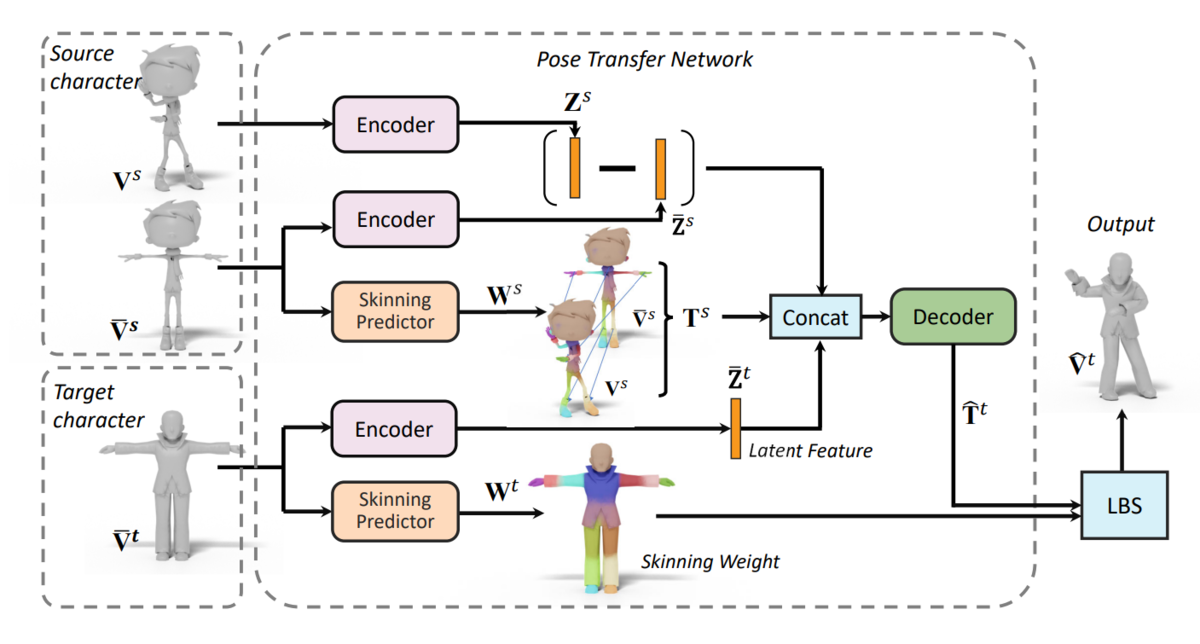
- ソースのニュートラルポーズとポーズ後に対してそれぞれGraph Convolution NetworkベースのEncoderを適用し、二つの特徴量が近い値になるようにする(Identityをキープしようとするネットワーク)
- ソースのニュートラルポーズとポーズ後間でトポロジーが同一のため、スキニングウェイトを推定するネットワークを通じて二つのメッシュ間の変形ジョイントの行列T_hatを計算可能。
- ターゲットのニュートラルポーズからEncoderを通じて特徴量を計算し、ソースの情報を集約することでリターゲットの変形ジョイントTを推定。
- ターゲットのニュートラルポーズからスキニングウェイトを推定し、T_hatを適用し、ポーズ後の形状を計算。
ジョイントの数はキャラクタによって異なりますが、本ネットワークでは40個として計算しているそうです。実際にスキニングウェイトはこのジョイント数に基づいて計算されますが、不要なジョイントはウェイト0として計算されるそうなので、キャラクタごとに適切なジョイントの数がウェイトから計算される点が非常に面白いと思いました。
使用するデータセット
上記学習を行うためにはポーズ前とポーズ後のペアデータセットが必要となります。彼らの研究では、AMASSデータセットとMixamoで作成したデータセットを用いているようです。特にAMASSデータはSMPLがベースになっているため、ポーズのパラメータを変えながらポーズは同一にすることでデータを多く作成しているようです。また、Mixamoのデータセットでは公開されている100以上のキャラクタと2000種類以上のモーションから異なるキャラクタ間で同じポーズをしているデータセットを作成しているそうです。
さらに面白いのは上記のデータセットだけでなく、RigNetのデータセットも用いている点。
こちらの記事でRigNetが少しだけ紹介されています。 iwanao731.hatenablog.com
RigNetは様々な形状のキャラクタに対してRiggingが施されていますが、共通のポーズデータは存在しません。そこで用いているのがCycle Consistency Loss。こちらは、Vs, V'sの変形を一旦Vtに適用して作成したV't'を、今度はVt, V't', Vsを用いてV's'を計算し直し、V'sとV's'の誤差を最小化しようとするもの。説明すると少しわかりづらいですが、ターゲットで予想された変形からソースの変形を生成し、正解と一致するかどうかを計算しています。近年のスキニング変形系の論文ではこのLossが広く用いられている気がします。ただし、これだけだと、圧倒的にニュートラルポーズのデータが多く、ポーズ後のデータが少ないため、安定しない問題があるようなので、上記のLossに加えて、ソースの変形を無理やりターゲットに適用して疑似的に作ったターゲットとCycle Consistency Lossで計算したターゲットの形状の誤差もとっているそうです。(細かい表記はうまく表示できていないかもしれないので当てにしないでください><)

本ブログではこれ以上は詳しくは書きませんが、上記に加えて下記を元に最適化を行っているようです。下記著者ポスターより引用
- 頂点間の距離の誤差
- 変形行列間の誤差
- スキンウェイトの誤差
- エッジ距離の誤差

結果
彼らの論文では、NBSとPinnocchio、Skeleton-aware Network (SAN) 、 Shape Pose Disentangle (SPD)の手法と比較を行っています。

比較手法としては、Point-wise Mesh Euclidean Distance(PMD)というMetricを採用しているそうです。詳しくは調べていないですが、正解メッシュと推定メッシュの対応頂点間のユークリッド距離の総和を誤差にしていると思われます。
結果をみるとPinnochioが意外とうまくいっているというのと、提案手法はきれいにできているなという印象です。ちなみにリターゲットで計算されている行列Tは階層構造がない単独のJointであるため、従来のアニメーションシステムの中で手動でポーズを変えた結果を反映したい場合に、前のジョイントの変形を引き継ぐ、といったことはできないと予想されます。その場合はソースモデルを変形することで対応できそうです。
比較論文の一部はこちらでも簡単に紹介しています。 iwanao731.hatenablog.com
まとめ
ポーズ前とポーズ後のメッシュからポーズ後のターゲットメッシュを作成できる研究を今回紹介しました。リターゲットを考える際に結果的にリギングをしている(スキニングウェイトやジョイントを計算している)のが面白いですね。ただし、本手法はターゲットのニュートラルポーズ(Tポーズ)が必要というのがLimitationだそうです。アーティストが作成した3Dモデルはだいたいニュートラルポーズで作られていますが、ぬいぐるみやフィギュア、マネキンなどはだいたいポーズが付けられてしまっているので、それをスキャンして別のポーズにしたいといった場合には適用するのが難しそうです。こういったケースに対応するために、今後はポーズ後をポーズ前(ニュートラルポーズ)に変形する手法[ 関連研究 ]があるとよさそうですね!