論文紹介: Learning Formation of Physically-Based Face Attributes
こんにちは。iwanao731です。2日連続の投稿です。表情生成のあたりを知りたくなったので、最近よく調べています。表情の研究って技術的にはやることたくさんあるし、コロナ禍の中でリモートでのコミュニケーションが大事になってくるというので、今後非常に重要になってくる技術であります。ですが、個人的にそれ以上の用途が浮かばないというか、ワクワクするような利用用途みたいなところがいまいち思い浮かばないし、結構どこのラボも同じようなモチベーションでやっているので、全然違う視点のアプリケーションや研究を見つけたいな、という気持ちがあったりはします。まぁアイデアはないんですが。。。
概要
Learning Formation of Physically-Based Face Attributes
Li et al., CVPR 2020
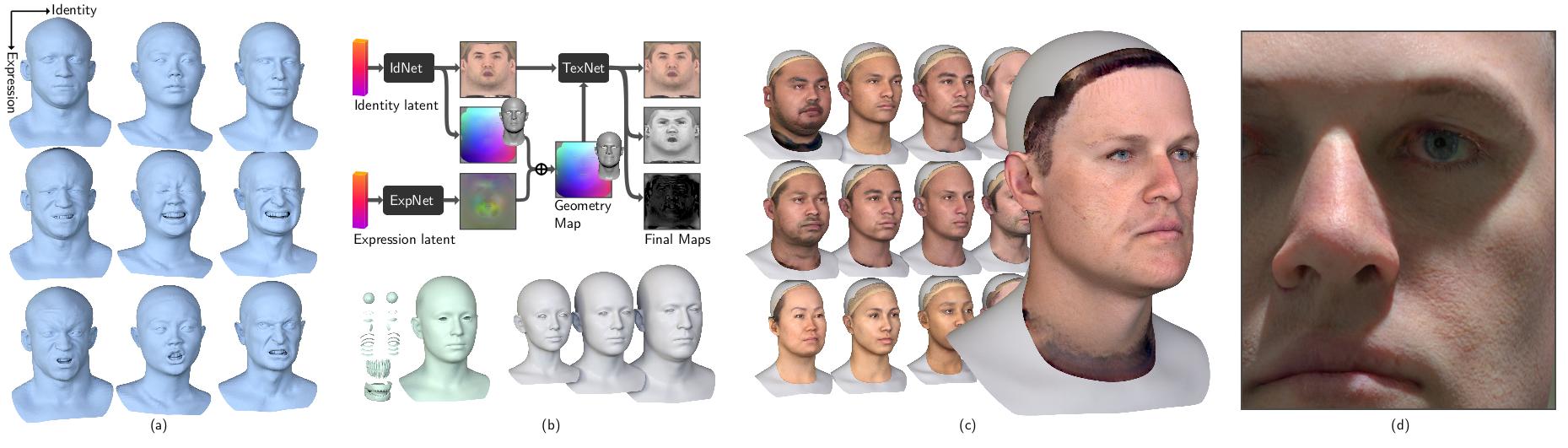
High FidelityなGenerative Face(Head) modelの提案。GANを使い、FaceのIdentityや表情、mid/high frequencyなgeometry、albedo、specularといったリアルなデジタルアバターに必要なデータを制御可能。何千パターンものHigh FidelityなHeadを生成することができる。
関連研究
ハイクオリティな顔のモデルを作るのは非常に手間がかかるため、実際に存在する/した人であれば過去の写真等から顔の形状を再現できたりすれば理想である。
それ以外に、実際に存在しない人であっても、パラメータ調整によって色んなバリエーションの高精細な表情モデルができたらそれも面白いかもしれない。1999年のSIGGRAPHで発表された3D Morphable Model (3DMM) はまさにそのコンセプトを実現した最初の研究である。3DMMは、様々なスキャンした顔の形状とテクスチャをPCAで圧縮し、次元を変えるだけで様々な人の顔をパラメトリックに生成することを可能にした。そんなMorphableモデルの過去、現在、未来をまとめた論文があるようなので気になる方はそちらを見てみるのも良いかもしれない。 [ 論文 ]
顔の領域だけだったMorphable Modelから、頭部のパラメトリックモデルを実現したFLAMEという論文は、表情やIdentityだけでなく、首の回転などの要素もすべてパラメトリックにした。こちらのモデルではテクスチャはついておらず、顔の詳細な情報も考慮はしていない。
毛穴レベルの形状は再現できなかったり、近年の物理ベースレンダリングのためのテクスチャアセットがなかったりして、過去のパラメトリックな顔モデルは高精細なデジタルアバター表現には不十分であった。もちろんLight Stageを使ってクオリティの高いテクスチャや形状を得ることは可能であるが、コストも時間もかかってしまうため、Morphable Modelの高解像度版を作りたい、というのが本論文の目的に親しい。
近年だとHao Liのグループが写真一枚から高精度な表情をモデリングする技術を発表している。これらの論文は、写真一枚から、テクスチャのalbedoを皮膚レベルにアップサンプリングしたり、mid/highレベルのgeometry mapを生成したり、specular mapを生成したりとデジタルアター生成技術に大きな貢献を果たしている。
これらの手法のlimitationを敢えて挙げるとするならば、写真一枚を入力しないとモデルが生成できない点にある。本論文では、外部のパラメータを与えるだけで様々なバリエーションのアバターを生成してくれる技術をGANを応用することによって実現している。
提案手法

本論文では、入力として、IdentityとExpression情報が必要となる。IdentityからUV空間のテクスチャとジオメトリ情報を生成し、Expressionからは、blendshapeのoffsetを生成する。IdentityのGeometryにoffsetを足すことによって表情を作り、一方でアップアンプリングしたテクスチャをTexture Inferenceに送ることで1Kのalbedo, specular, geometry mapが生成される。そのmapをExpression Geometryに加えることで高精細なアバターを生成する。
顔モデル

高精細なアバター生成に必要なモデル情報が含まれている。
使用したデータセット
- Light Stageで撮影した18-67歳の男女。女性34名, 男性45名の計79名。各アクターから40個のFACのうち、選定した26個の表情を取得。(albedo,geometry,specular, expression)
- triplegangersというサイトから選定した99名のアクター。各アクターごとに表情は20個。(上記に比べ、specularのtextureなし)
個人の顔モデリング
顔の形状とテクスチャ(albedo)は相関関係があるという仮定のもと、Style-GAN Architectureを用いて、高精細かつ制御可能な顔を学習する。
Identity情報からalbedoのテクスチャと頂点位置情報(geometry)のテクスチャを生成。整合性を保つために、以下の3つのdiscriminatorを用意している。

- 生成したtextureがGround Truthに近いか。
- 生成したgeometryがGround Truthに近いか。
- 生成したtextureとgeometryの組み合わせがGround Truthに近いか。
表情のモデリング
表情の学習を簡易化するために、geometry情報をUV空間のテクスチャ情報に落とし込み、neutral表情との差分をoffsetとしてテクスチャを生成している。Identity Networkと同様にStyle-GAN Architectureを使用。Networkへの入力として、FACSの表情25個に対するブレンドシェイプウェイトを使用。

- R_expでは、生成されたoffset textureからblend weightを推定し、またそのウェイトから生成するようになっている。
- D_expはGround Truthに近いかどうか。
高解像度化
高解像度化に関しては、Yamaguchiらと同様の手法を利用。彼らがalbedoのみを入力としているのに対し、geometry mapを使用。Huynhらの手法と同様にmid/high frequency textureを生成し、upsampling [ 論文 ]。
結果


他手法に比べて、非常にオリジナルに近い形状が得られている。この結果を得るために、入力画像のLatent spaceを知るための技術 [ 論文 ]を利用。また、Geometryの形状は、Laplacian morphingを利用。

ドメインが同じであれば、それに基づいた詳細モデルを生成可能。

表情の補間も可能。表情のパラメータが0.0-1.0じゃないので、従来のblendshapeのウェイトとはまた異なるルールが必要かもしれない。
今後の課題
- IdentityとExpressionがそれぞれ独立しているので、個性を考慮した表情を作ることが難しい上に、生成されたExpression offset textureはidentity expressionのmiddle frequencyが含まれていない。
- 今後は、この相関関係を考慮することが課題。
- 表情生成に、ニューラルネットワークのArchitextureと3D geometryのresamplingが必要になるので、facialのretargetが未だできていない。
- 入力画像からIdentityを推定するために、differentiable rendererのような仕組みが必要。
- ライティングによって結果が変わるかもしれない。
雑感
- 写真一枚からアバター生成といったアプリケーション用途ではまだ利用は難しい印象。
- たくさんそれっぽいアバターを作るという話だったら色々と使いやすそう。
- 表情のリターゲットもまだ制御が難しそうなのと、個人の顔とその表情の相関関係を考慮するのは今後必須になってきそう。